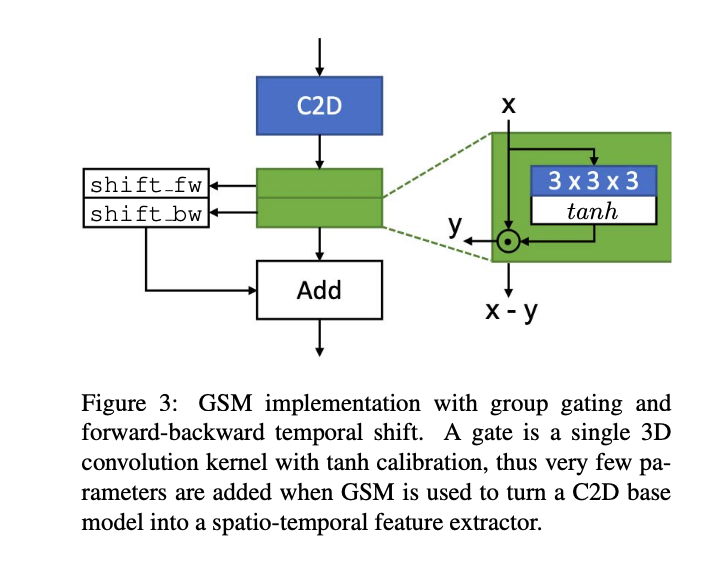
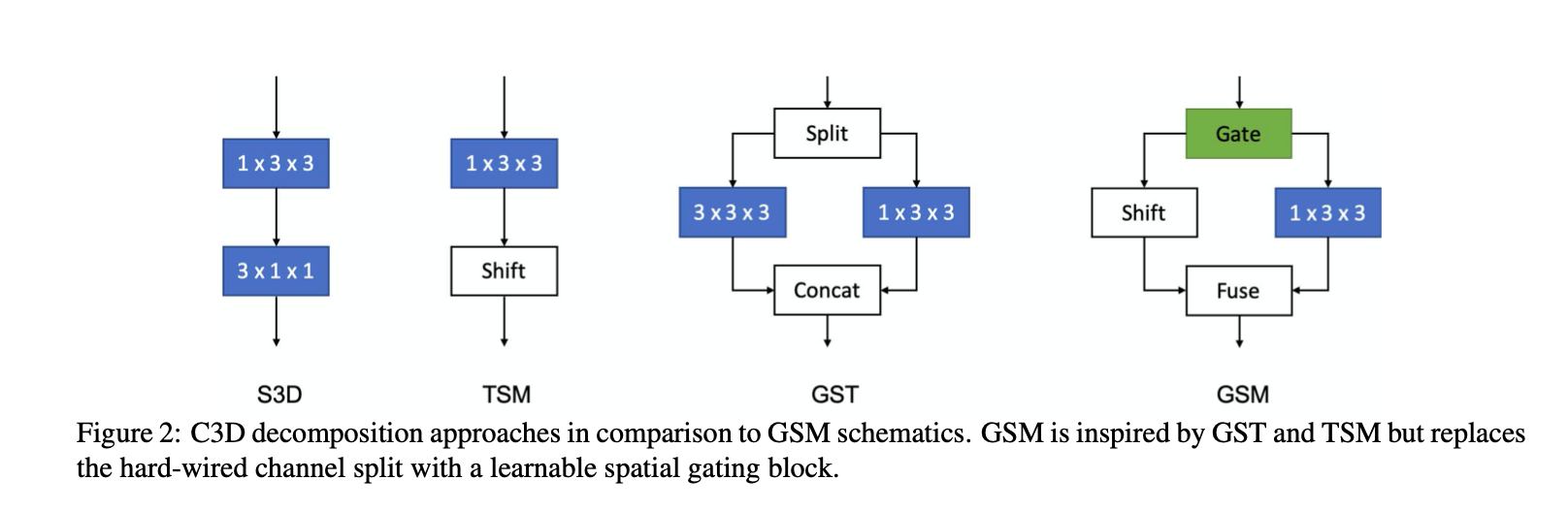
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
| $ python test_models.py somethingv2 --VAP --batch_size=16 -j=4 --test_crops=1 --test_segments=8 --weights=pretrained/PAN_Lite_somethingv2_resnet50_shift8_blockres_avg_segment8_e80.pth.tar
somethingv2: 174 classes
=> shift: True, shift_div: 8, shift_place: blockres
=> base model: resnet50
=> Adding temporal shift...
=> Using 3-level VAP
=> Converting the ImageNet model to a PAN_Lite init model
=> Done. PAN_lite model ready...
video number:24777
video 0 done, total 0/24777, average 4.263 sec/video, moving Prec@1 56.250 Prec@5 81.250
video 320 done, total 320/24777, average 0.481 sec/video, moving Prec@1 65.476 Prec@5 86.310
video 640 done, total 640/24777, average 0.399 sec/video, moving Prec@1 60.976 Prec@5 85.213
video 960 done, total 960/24777, average 0.452 sec/video, moving Prec@1 60.246 Prec@5 85.348
video 1280 done, total 1280/24777, average 0.424 sec/video, moving Prec@1 60.880 Prec@5 85.802
video 1600 done, total 1600/24777, average 0.400 sec/video, moving Prec@1 60.458 Prec@5 85.334
video 1920 done, total 1920/24777, average 0.397 sec/video, moving Prec@1 60.227 Prec@5 85.537
video 2240 done, total 2240/24777, average 0.398 sec/video, moving Prec@1 60.151 Prec@5 85.594
video 2560 done, total 2560/24777, average 0.390 sec/video, moving Prec@1 60.404 Prec@5 85.637
video 2880 done, total 2880/24777, average 0.388 sec/video, moving Prec@1 60.290 Prec@5 85.463
video 3200 done, total 3200/24777, average 0.386 sec/video, moving Prec@1 60.261 Prec@5 85.572
video 3520 done, total 3520/24777, average 0.380 sec/video, moving Prec@1 60.436 Prec@5 85.605
video 3840 done, total 3840/24777, average 0.372 sec/video, moving Prec@1 60.062 Prec@5 85.425
video 4160 done, total 4160/24777, average 0.368 sec/video, moving Prec@1 59.962 Prec@5 85.321
video 4480 done, total 4480/24777, average 0.367 sec/video, moving Prec@1 59.831 Prec@5 85.343
video 4800 done, total 4800/24777, average 0.365 sec/video, moving Prec@1 59.884 Prec@5 85.507
video 5120 done, total 5120/24777, average 0.362 sec/video, moving Prec@1 60.008 Prec@5 85.533
video 5440 done, total 5440/24777, average 0.358 sec/video, moving Prec@1 60.392 Prec@5 85.521
video 5760 done, total 5760/24777, average 0.355 sec/video, moving Prec@1 60.336 Prec@5 85.457
video 6080 done, total 6080/24777, average 0.352 sec/video, moving Prec@1 60.285 Prec@5 85.400
video 6400 done, total 6400/24777, average 0.351 sec/video, moving Prec@1 59.804 Prec@5 85.318
video 6720 done, total 6720/24777, average 0.348 sec/video, moving Prec@1 59.650 Prec@5 85.125
video 7040 done, total 7040/24777, average 0.347 sec/video, moving Prec@1 59.736 Prec@5 85.204
video 7360 done, total 7360/24777, average 0.344 sec/video, moving Prec@1 59.585 Prec@5 85.182
video 7680 done, total 7680/24777, average 0.342 sec/video, moving Prec@1 59.771 Prec@5 85.265
video 8000 done, total 8000/24777, average 0.341 sec/video, moving Prec@1 59.681 Prec@5 85.292
video 8320 done, total 8320/24777, average 0.339 sec/video, moving Prec@1 59.633 Prec@5 85.281
video 8640 done, total 8640/24777, average 0.337 sec/video, moving Prec@1 59.635 Prec@5 85.386
video 8960 done, total 8960/24777, average 0.336 sec/video, moving Prec@1 59.548 Prec@5 85.316
video 9280 done, total 9280/24777, average 0.334 sec/video, moving Prec@1 59.477 Prec@5 85.273
video 9600 done, total 9600/24777, average 0.333 sec/video, moving Prec@1 59.536 Prec@5 85.358
video 9920 done, total 9920/24777, average 0.331 sec/video, moving Prec@1 59.652 Prec@5 85.397
video 10240 done, total 10240/24777, average 0.331 sec/video, moving Prec@1 59.565 Prec@5 85.413
video 10560 done, total 10560/24777, average 0.330 sec/video, moving Prec@1 59.503 Prec@5 85.354
video 10880 done, total 10880/24777, average 0.329 sec/video, moving Prec@1 59.554 Prec@5 85.380
video 11200 done, total 11200/24777, average 0.330 sec/video, moving Prec@1 59.576 Prec@5 85.396
video 11520 done, total 11520/24777, average 0.329 sec/video, moving Prec@1 59.639 Prec@5 85.480
video 11840 done, total 11840/24777, average 0.327 sec/video, moving Prec@1 59.691 Prec@5 85.417
video 12160 done, total 12160/24777, average 0.326 sec/video, moving Prec@1 59.675 Prec@5 85.422
video 12480 done, total 12480/24777, average 0.325 sec/video, moving Prec@1 59.675 Prec@5 85.451
video 12800 done, total 12800/24777, average 0.325 sec/video, moving Prec@1 59.691 Prec@5 85.471
video 13120 done, total 13120/24777, average 0.324 sec/video, moving Prec@1 59.645 Prec@5 85.490
video 13440 done, total 13440/24777, average 0.323 sec/video, moving Prec@1 59.617 Prec@5 85.486
video 13760 done, total 13760/24777, average 0.322 sec/video, moving Prec@1 59.640 Prec@5 85.475
video 14080 done, total 14080/24777, average 0.321 sec/video, moving Prec@1 59.641 Prec@5 85.464
video 14400 done, total 14400/24777, average 0.322 sec/video, moving Prec@1 59.600 Prec@5 85.502
video 14720 done, total 14720/24777, average 0.323 sec/video, moving Prec@1 59.521 Prec@5 85.437
video 15040 done, total 15040/24777, average 0.323 sec/video, moving Prec@1 59.358 Prec@5 85.355
video 15360 done, total 15360/24777, average 0.323 sec/video, moving Prec@1 59.365 Prec@5 85.341
video 15680 done, total 15680/24777, average 0.322 sec/video, moving Prec@1 59.353 Prec@5 85.302
video 16000 done, total 16000/24777, average 0.321 sec/video, moving Prec@1 59.328 Prec@5 85.340
video 16320 done, total 16320/24777, average 0.322 sec/video, moving Prec@1 59.341 Prec@5 85.327
video 16640 done, total 16640/24777, average 0.320 sec/video, moving Prec@1 59.312 Prec@5 85.315
video 16960 done, total 16960/24777, average 0.320 sec/video, moving Prec@1 59.295 Prec@5 85.315
video 17280 done, total 17280/24777, average 0.320 sec/video, moving Prec@1 59.256 Prec@5 85.291
video 17600 done, total 17600/24777, average 0.321 sec/video, moving Prec@1 59.191 Prec@5 85.280
video 17920 done, total 17920/24777, average 0.321 sec/video, moving Prec@1 59.066 Prec@5 85.220
video 18240 done, total 18240/24777, average 0.321 sec/video, moving Prec@1 59.109 Prec@5 85.232
video 18560 done, total 18560/24777, average 0.321 sec/video, moving Prec@1 59.189 Prec@5 85.255
video 18880 done, total 18880/24777, average 0.320 sec/video, moving Prec@1 59.113 Prec@5 85.198
video 19200 done, total 19200/24777, average 0.319 sec/video, moving Prec@1 59.128 Prec@5 85.205
video 19520 done, total 19520/24777, average 0.319 sec/video, moving Prec@1 59.142 Prec@5 85.227
video 19840 done, total 19840/24777, average 0.319 sec/video, moving Prec@1 59.136 Prec@5 85.244
video 20160 done, total 20160/24777, average 0.320 sec/video, moving Prec@1 59.199 Prec@5 85.255
video 20480 done, total 20480/24777, average 0.320 sec/video, moving Prec@1 59.202 Prec@5 85.290
video 20800 done, total 20800/24777, average 0.319 sec/video, moving Prec@1 59.204 Prec@5 85.295
video 21120 done, total 21120/24777, average 0.319 sec/video, moving Prec@1 59.226 Prec@5 85.328
video 21440 done, total 21440/24777, average 0.318 sec/video, moving Prec@1 59.270 Prec@5 85.314
video 21760 done, total 21760/24777, average 0.318 sec/video, moving Prec@1 59.285 Prec@5 85.342
video 22080 done, total 22080/24777, average 0.318 sec/video, moving Prec@1 59.314 Prec@5 85.355
video 22400 done, total 22400/24777, average 0.318 sec/video, moving Prec@1 59.284 Prec@5 85.377
video 22720 done, total 22720/24777, average 0.318 sec/video, moving Prec@1 59.236 Prec@5 85.340
video 23040 done, total 23040/24777, average 0.317 sec/video, moving Prec@1 59.256 Prec@5 85.414
video 23360 done, total 23360/24777, average 0.317 sec/video, moving Prec@1 59.274 Prec@5 85.417
video 23680 done, total 23680/24777, average 0.317 sec/video, moving Prec@1 59.246 Prec@5 85.403
video 24000 done, total 24000/24777, average 0.318 sec/video, moving Prec@1 59.231 Prec@5 85.389
video 24320 done, total 24320/24777, average 0.317 sec/video, moving Prec@1 59.291 Prec@5 85.413
video 24640 done, total 24640/24777, average 0.317 sec/video, moving Prec@1 59.259 Prec@5 85.436
[0.84482759 0.38815789 0.51633987 0.58252427 0.58974359 0.54385965
0.76738609 0.63636364 0.67716535 0.60264901 0.53932584 0.68613139
0.26923077 0.425 0.7122807 0.51914894 0.42639594 0.38157895
0.46025105 0.57345972 0.51574803 0.62280702 0.55232558 0.56382979
0.56818182 0.52631579 0.6 0.48514851 0.71818182 0.77394636
0.78378378 0.77477477 0.82954545 0.11650485 0.36144578 0.203125
0.84331797 0.82129278 0.22222222 0.79411765 0.71584699 0.73214286
0.59624413 0.62057878 0.72972973 0.51253482 0.5873494 0.40703518
0.42857143 0.80430108 0.7257384 0.06666667 0.40625 0.68571429
0.25 0.42 0.4109589 0.60377358 0.17647059 0.81654676
0.92 0.21568627 0.73417722 0.30841121 0.21621622 0.53301887
0.30188679 0.40298507 0.6754386 0.43 0.64285714 0.47826087
0.54411765 0.61538462 0.66981132 0.36842105 0.5 0.30769231
0.2962963 0.77586207 0.296875 0.168 0.36170213 0.44680851
0.64 0.44444444 0.85882353 0.792 0.25 0.19277108
0.56521739 0.85 0.57894737 0.764 0.76694915 0.13888889
0.14705882 0.2892562 0.51020408 0.67765568 0.46792453 0.62637363
0.29310345 0.8125 0.7480315 0.73333333 0.52054795 0.66502463
0.39189189 0.48 0.6056338 0.05555556 0.49640288 0.27777778
0.69097222 0.54347826 0.25925926 0.77777778 0.40677966 0.64356436
0.80314961 0.80681818 0.34975369 0.69230769 0.36538462 0.63761468
0.55339806 0.42608696 0.1302682 0.70955882 0.32142857 0.35616438
0.44827586 0.24561404 0.79619565 0.62269939 0.23529412 0.45
0.24770642 0.72727273 0.6627907 0.359375 0.59375 0.63311688
0.56050955 0.44680851 0.74166667 0.0859375 0.55230126 0.90754717
0.76902174 0.33152174 0.3877551 0.75229358 0.51181102 0.29268293
0.5 0.58695652 0.55045872 0.34545455 0.41284404 0.46052632
0.43925234 0.45 0.84398977 0.88709677 0.96428571 0.94444444
0.81666667 0.70666667 0.45098039 0.72115385 0.74418605 0.65693431]
upper bound: 0.548518228331384
-----Evaluation is finished------
Class Accuracy 53.84%
Overall Prec@1 59.26% Prec@5 85.45%
E:\Program Files\Anaconda3\envs\tsm\lib\site-packages\numpy\core\_asarray.py:136: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return array(a, dtype, copy=False, order=order, subok=True)
|