工作计划-20201102
| 2020-11-02 | 工作计划#01 | 刘潘 |
|---|
| 2020-11-02 | 工作计划#01 | 刘潘 |
|---|
提示说:
shift_cuda.cpp:18:26: error: ‘THCState_getCurrentStream’ was not declared in this scope
| 2020-10-29 | 周报#10 | 刘潘 |
|---|
| 2020-10-22 | 周报#09 | 刘潘 |
|---|
主要的创新点是MS module,它把这个结构插入到了ResNet的网络中间,具体来说在layer2之后,layer3之前。
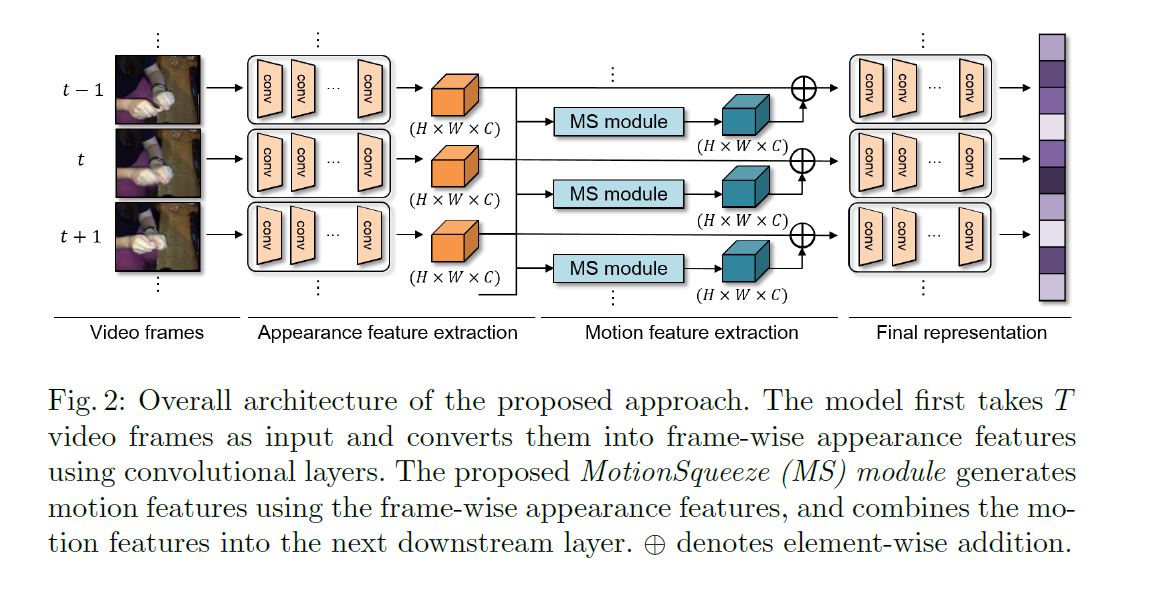
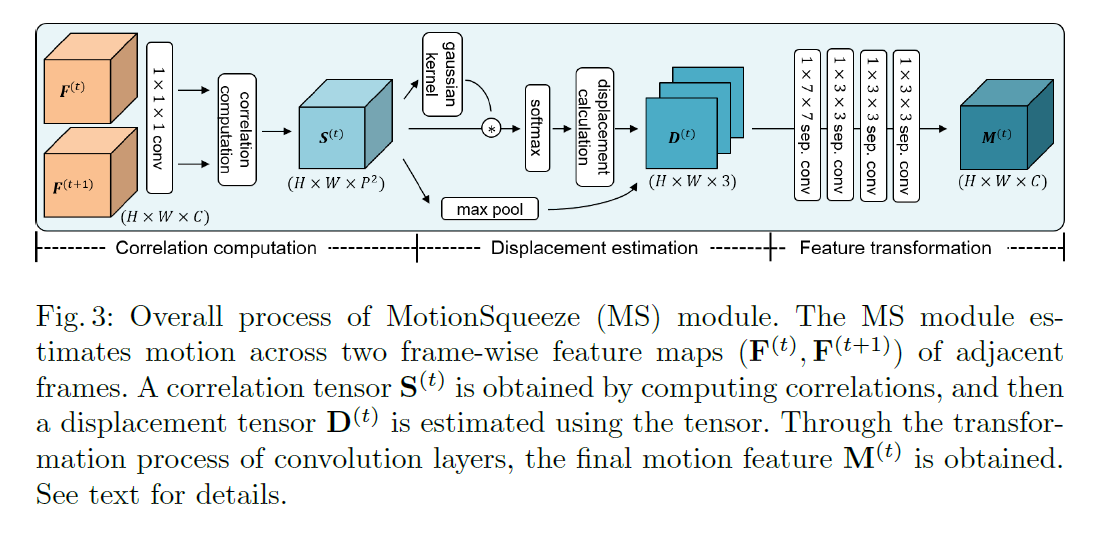
逻辑上如下图所示,道理上说得很清楚,首先进行关联性计算,就是为了判断当前的点可能会位移到什么位置,即什么位置的点最有可能是由当前的点位移过去的。
然后通过估计上的点,计算偏移。
最后计算特征转换。(这个其实我没太理解)
论文中需要引用这边论文的一个结论,记录之。原来我之前就记录过,但是没有写笔记,导致我昨晚(20201228)突然想找这个结论的时候记不得是哪篇论文了,所幸找到了,不然几百篇参考文献我真是要翻到吐,万一里面还没有,那才是绝望。
其实这篇文章的TRN好像也是我所研究的TSN发展历程上的一个点,但没有细看过,说来惭愧。不过这个的效果大多已经被后面的TSM和TEA之类的取代了。
论文为了验证时序信息的重要性,对比了顺序帧和乱序帧在同一网络下的识别准确率,分别在UCF101和something-something上进行测试,证明了两点:
something-something这类数据集,时序性很强,不是通过场景就能判断识别结果的。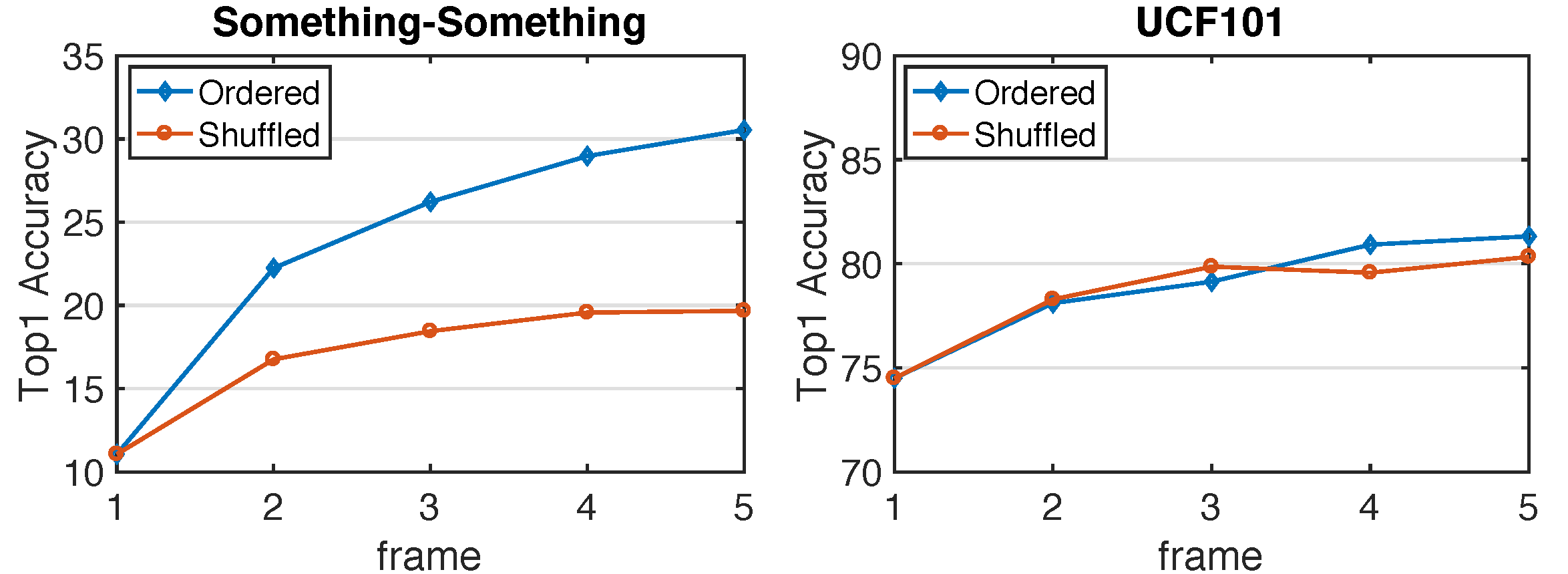
进一步,作者对比了随机和顺序中识别准确率差别最大的几类,发现具有单一方向的较大位移运动受影响最大,比如Moving something down。
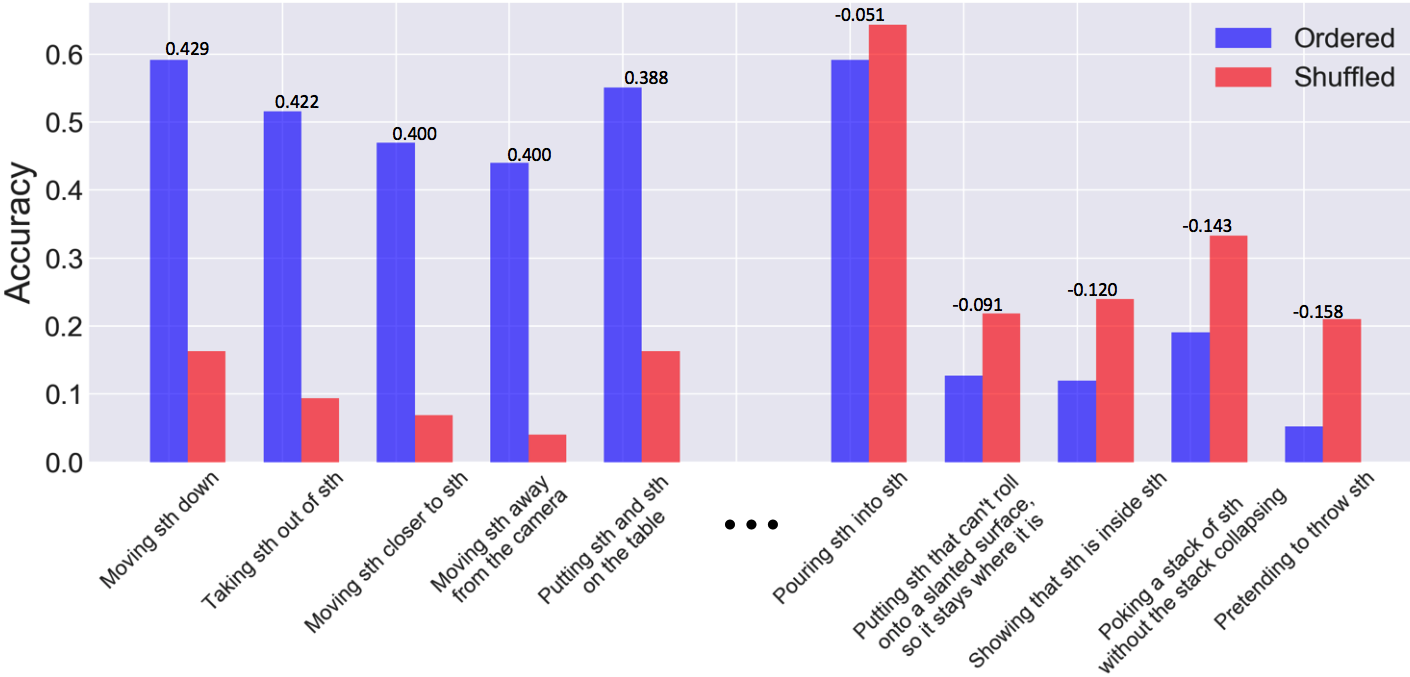
不过也有可能存在一些变高的识别结果,这个原因我没太看懂= =
在本文中,我们提出了一个受光流算法启发的卷积层来学习运动表示。我们的表示流层是完全可微的层,设计用于捕获卷积神经网络内任何表示通道的流,用于动作识别。其迭代流优化参数与其他CNN模型参数以端到端的方式学习,最大限度地提高动作识别性能。此外,我们通过堆叠多个表示流池,引入了流表示学习流的概念。我们进行了广泛的实验评估,证实了其在计算速度和性能上优于以往使用传统光流的识别模型。该代码是公开的。
表示流中再计算一次流。。。结果是下降的,这就和我PAN里的实验结论一致。