列表2024
Contents
#最近做的事
#MySQL 锁相关
#Golang
#awk 相关
对于 linux 随系统提供的软件,不同系统可能有不同的版本,可能有些 api 不同,需要在编写跨机器脚本时注意:
1 | ┌ [2024/05/19 20:19:28] aliyun ~/.onns/code/bash |
alternatives是用来管理多个可执行程序的工具
#tmux+alacritty 配置
通过配置可以实现切换不同的 session 和 window,解决了 alacritty 没有 tab 的问题
https://github.com/alacritty/alacritty/issues/5680
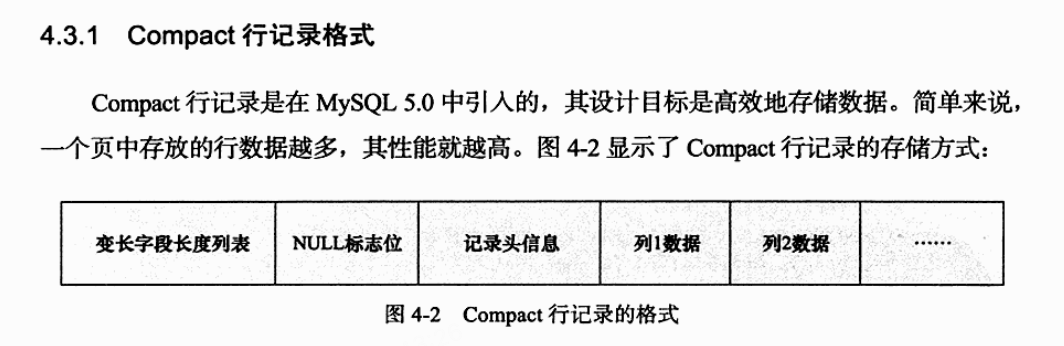
#行格式(row_format)
博客再多,不如官方文档来得详细清楚:MySQL :: MySQL 8.4 Reference Manual :: 17.10 InnoDB Row Formats
The
DYNAMICrow format offers the same storage characteristics as theCOMPACTrow format but adds enhanced storage capabilities for long variable-length columns and supports large index key prefixes.
When a table is created withROW_FORMAT=DYNAMIC,InnoDBcan store long variable-length column values (forVARCHAR,VARBINARY, andBLOBandTEXTtypes) fully off-page, with the clustered index record containing only a 20-byte pointer to the overflow page. Fixed-length fields greater than or equal to 768 bytes are encoded as variable-length fields. For example, aCHAR(255)column can exceed 768 bytes if the maximum byte length of the character set is greater than 3, as it is withutf8mb4.
目前默认的DYNAMIC行格式是在COMPACT上进行的升级。
#行大小限制
一直以来知道的都是 varchar 最大 65535 字节,原来这个限制是整个行的大小限制。
MySQL :: MySQL 8.4 Reference Manual :: 10.4.7 Limits on Table Column Count and Row Size
几个疑问:
- InnoDB 为什么限制一页(默认 16KB)最少 2 条记录

- 一行最多 65535bytes,为什么
- mysql 限制行最大 65535bytes,innodb 可以通过溢出存储更多数据,为什么还要遵守这个限制
第三个问题贴个 gpt 的回答:
MySQL 中的行大小限制为 65535 字节(bytes),这个限制是由于 MySQL 表结构的固有设计决定的。尽管 InnoDB 存储引擎可以通过溢出页来存储更大数据,但这个行大小限制仍然存在,主要有以下几个原因:
- 表结构的设计限制: MySQL 表的行大小限制为 65535 字节,这是由于 MySQL 的表定义结构决定的。每个表的行长度在表定义阶段就被限制在这个范围内。这是一个静态限制,无法通过任何存储引擎的特性来绕过。
- 数据页结构的设计: InnoDB 的每个数据页(page)的大小通常为 16KB。尽管 InnoDB 可以将大字段存储在溢出页中,但主记录页仍然需要存储一定量的列数据和元数据。如果单行数据过大,可能导致主记录页无法容纳基本的元数据。
- 内存和缓存管理: 在内存和缓存管理方面,遵守 65535 字节的行大小限制可以简化数据库的缓存策略和内存管理。过大的行可能会导致内存管理和缓存命中的复杂性增加,从而影响数据库的性能。
- 一致性和回滚支持: InnoDB 在处理事务时,需要确保数据的一致性和支持回滚操作。单行数据过大可能会增加事务日志和回滚日志的复杂性,影响数据库的性能和可靠性。
- 简化数据库设计和维护: 遵守行大小限制可以使数据库设计和维护更为简单和一致。开发者在设计数据库时,可以预先考虑行大小限制,避免在实际使用中遇到数据超限的问题。
尽管 InnoDB 通过溢出页技术可以存储更多的数据,但 MySQL 的行大小限制仍然需要遵守。这是为了保证数据库的稳定性、一致性和性能,同时也使数据库设计和管理更加简便。
#golang 格式化
mvdan/gofumpt: A stricter gofmt (github.com)
比标准的格式化更严格
#InnoDB 行读取
- The physical structure of records in InnoDB – Jeremy Cole (jcole.us)
- mysql 学习-Innodb 行格式 compact 行记录解析_为什么变长字段长度列表的信息要按照逆序存放?-CSDN 博客
一直有个疑问,变长字段是怎么读取的,既没有明确的分隔符,又没有长度标识。
多方查证后:
- 前置知识需要知道这行数据:多少个可空字段,以及,多少个变长字段
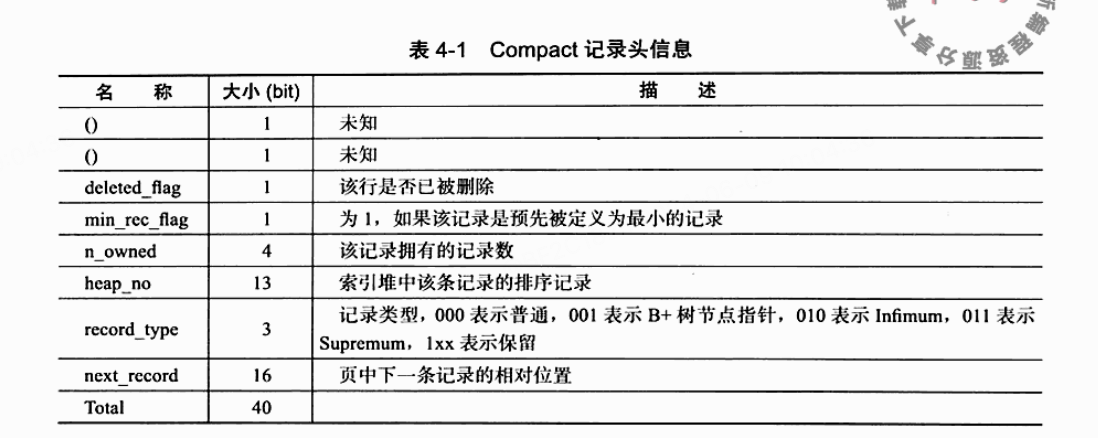
- innodb 和 redis 的 sds 类似,指针指向数据的时候,指向的是真实数据的首位,该位置前方是记录头信息
- null 标识和变长字段长度列表都是逆序存放,所以也逆序读取
- null 字符被补齐为 8 的倍数,用比特位代表字段是否为空,为空不占用真实数据部分任何空间
- 一个字节本来可以表示 0-255,但是在 mysql 中只能用来表示 0-127,最高位若是 1,则代表长度数据需要 2 个字节,因此无需标注也可以确保读取完整数据
- 记录头信息(record header)中有 16 位的下一个记录的相对位置,代表的也是数据部分,且 16 位只能代表 0-65535
衍生出几个问题和几个结论:
- 为什么行长度只能是 65535?因为代表下一个数据的偏移只有 2 字节,只能偏移 65535
- 为什么都建议字段 NOT NULL?
- null 字段和空串有什么区别?
#MySQL 视图
java - 开发中何时使用数据库视图? - SegmentFault 思否
感觉是个日常开发不太会使用的功能,了解下来主要的用途是在 MySQL 层面对外做权限控制,即隐藏底层基础表,整合数据后,对外只提供针对视图的读取账号。
读书时先行跳过。
#MySQL 索引
B+树索引并不能找到一个给定键值的具体行。B+树索引能找到的只是被查找数据行所在的页。然后数据库通过把页读入到内存,再在内存中进行查找,最后得到要查找的数据。
- 对于 B+树,如果主键一直自增那如果均匀分裂,前半部分的树永远都不会被使用,所以会有插入方向字段,用于控制分裂方向。(疑问点,这样设计真的会解决这个问题嘛?)

#取模
模运算中为何要用素数作为模 | 断鸿声里,立尽斜阳 (flat2010.github.io)
#MySQL 重做日志
#swap
云服务器经常因为内存爆掉,所以需要开启 swap 虚拟内存:
Debian / Ubuntu 手工添加 Swap 分区 - 烧饼博客
#MySQL 死锁
万字解析 mysql innodb 锁机制实现原理 (qq.com)
#zsh_history 配置
很多命令都在历史中,换设备时会重新输入,最简单的方案是从曾经的.zsh_history 文件中查找,但保存数量较少,一些不经常使用的命令已经无法追溯。
1 | HISTSIZE=999999999 |
大致参考:
#acme.sh 泛域名
之前一直用单域名证书,原来 acme 的也支持泛域名,而且支持 dns 验证,大佬 nb