《快乐的Linux命令行》笔记(汇总)
Contents
#《快乐的 Linux 命令行》
如果提示符的最后一个字符是#, 而不是$, 那么这个终端会话就有超级用户权限[1]。
许多Linux发行版默认保存最后输入的500个命令(就是上下键显示的那些)。
日历命令:
1 | $ cal |
cd -命令可以更改到上一个工作路径。
1 | % cd Documents/common/PAN-PyTorch |
Linux 文件命名的特殊符号仅支持.,-和_。
不要在文件名中使用空格。
ls的参数:
| 选项 | 长选项 | 描述 |
|---|---|---|
-r |
--reverse |
逆序输出 |
-t |
按照修改时间来排序 | |
-l |
以长格式显示结果 |
感觉-l参数是最常用的了,会输出一些有用的信息:
1 | onns@liupans-MacBook-Air blog % ls -l |
-rw-r--r--表示对文件的权限,第一个字符代表文件类型:
-代表是一个普通文件。d代表是一个目录。
后面的是权限字符,后面会讲。
1 代表硬链接的数目。
onns代表文件所有者的用户名。
staff代表所属用户组的组名。
2586是以字节数表示的文件大小。
最后是上次修改时间和文件名。
file命令用来查看文件的类型:
1 | onns@liupans-MacBook-Air image % file draw-20200207.jpg |
less命令用来浏览文本文件,是more命令的升级版:
1 | less filename |
| 选项 | 描述 |
|---|---|
| Page UP or b | 向上翻滚一页 |
| Page Down or space | 向下翻滚一页 |
| UP Arrow | 向上翻滚一行 |
| Down Arrow | 向下翻滚一行 |
| G | 移动到最后一行 |
| 1G or g | 移动到开头一行 |
| /charaters | 向前查找指定的字符串 |
| n | 向前查找下一个出现的字符串,这个字符串是之前所指定查找的 |
| h | 显示帮助屏幕 |
| q | 退出 less 程序 |
在 ls -l的时候,如果最前面的字符不是-也不是d而是l,代表是一个符号链接。
#通配符
*匹配任意多个字符(包括零个或一个)?匹配任意一个字符(不包括零个)[characters]匹配任意一个属于字符集中的字符[!characters]匹配任意一个不是字符集中的字符[[:class:]]匹配任意一个属于指定字符类中的字符
字符类
[:alnum:]匹配任意一个字母或数字[:alpha:]匹配任意一个字母[:digit:]匹配任意一个数字[:lower:]匹配任意一个小写字母[:upper:]匹配任意一个大写字母
一些示例:
*所有文件g*文件名以“g”开头的文件b*.txt以“b” 开头,中间有零个或任意多个字符,并以”.txt”结尾的文件Data???以Data开头,其后紧接着3个字符的文件[abc]*文件名以a、b或c开头的文件BACKUP.[0-9][0-9][0-9]以BACKUP.开头,并紧接着3个数字的文件[[:upper:]]*以大写字母开头的文件[![:digit:]]*不以数字开头的文件*[[:lower:]123]文件名以小写字母结尾,或以1、2或3结尾的文件
之前写正则时候的[A-Z]和[a-z]虽然都有效果,但是已经很老了,不一定会有期望的效果,可以弃用了。
虽然它们仍然起作用,但是你必须小心地使用它们,因为它们不会产生你期望的输出结果,除非你合理地配置它们。从现在开始,你应该避免使用它们,并且用字符类来代替它们。
#创建目录
命令:
1 | mkdir directory... |
上面命令的...代表那个参数可以重复,即可以一次性创建多个文件:
1 | mkdir dir1 dir2 dir3 |
会创建三个目录。
#复制文件和目录
两种用法:
1 | cp item1 item2 |
复制单个文件或目录item1到文件或目录item2。
1 | cp item1... directory |
复制多个项目(文件或目录)到一个目录下。
cp命令的一些参数选项:
| 选项 | 长选项 | 描述 |
|---|---|---|
-a |
--archive |
复制文件和目录,以及它们的属性,包括所有权和权限。通常,副本具有用户所操作文件的默认属性。 |
-i |
--interactive |
在重写已存在文件之前,提示用户确认。如果这个选项不指定,cp 命令会默认重写文件。 |
-r |
--recursive |
递归地复制目录及目录中的内容。当复制目录时,需要这个选项(或者-a 选项)。 |
-u |
--update |
当把文件从一个目录复制到另一个目录时,仅复制目标目录中不存在的文件,或者是文件内容新于目标目录中已经存在的文件。 |
-v |
--verbose |
显示详细的命令操作信息 |
示例:
cp file1 file2复制文件 file1 内容到文件 file2。如果 file2 已经存在,file2 的内容会被 file1 的内容重写。如果 file2 不存在,则会创建 file2。cp -i file1 file2这条命令和上面的命令一样,除了如果文件 file2 存在的话,在文件 file2 被重写之前,会提示用户确认信息。cp file1 file2 dir1复制文件 file1 和文件 file2 到目录 dir1。目录 dir1 必须存在。cp dir1/* dir2使用一个通配符,在目录 dir1 中的所有文件都被复制到目录 dir2 中。dir2 必须已经存在。cp -r dir1 dir2复制目录 dir1 中的内容到目录 dir2。如果目录 dir2 不存在,创建目录 dir2,操作完成后,目录 dir2 中的内容和 dir1 中的一样。如果目录 dir2 存在,则目录dir1和目录中的内容将会被复制到dir2中。
最后一个比较难理解,做个例子自己试一下!
#示例
首先创建一下测试的环境:
1 | onns@DESKTOP-5JJP7PL:~$ ls |
然后执行一下命令:
1 | onns@DESKTOP-5JJP7PL:~$ cp -r dir1 dir2 |
然后查看结果:
1 | onns@DESKTOP-5JJP7PL:~$ ls dir1 dir2 |
#移动文件
感觉mv和cp是一样的,只是不同的在于,mv移动文件夹的时候不需要-r,自动完成的。
两种用法:
1 | mv item1 item2 |
把文件或目录item1移动或重命名为item2。
1 | mv item1... directory |
把一个或多个条目从一个目录移动到另一个目录中。
mv命令的一些参数选项:
| 选项 | 长选项 | 描述 |
|---|---|---|
-i |
--interactive |
在重写一个已经存在的文件之前,提示用户确认信息。如果不指定这个选项,mv 命令会默认重写文件内容。 |
-u |
--update |
当把文件从一个目录移动另一个目录时,只是移动不存在的文件,或者文件内容新于目标目录相对应文件的内容。 |
-v |
--verbose |
显示详细的命令操作信息 |
示例:
mv file1 file2移动 file1 到 file2。如果 file2 存在,它的内容会被 file1 的内容重写。如果 file2 不存在,则创建 file2。这两种情况下,file1 都不再存在。mv -i file1 file2除了如果 file2 存在的话,在 file2 被重写之前,用户会得到提示信息外,这个和上面的选项一样。mv file1 file2 dir1移动 file1 和 file2 到目录 dir1 中。dir1 必须已经存在。mv dir1 dir2如果目录 dir2 不存在,创建目录 dir2,并且移动目录 dir1 的内容到目录 dir2 中,同时删除目录 dir1。如果目录 dir2 存在,移动目录dir1及它的内容到目录dir2。
#删除文件
1 | rm item... |
感觉在 linux 下第一个知道的命令大概就是rm -rf /*吧…
一些选项:
| 选项 | 长选项 | 描述 |
|---|---|---|
-i |
--interactive |
在删除已存在的文件前,提示用户确认信息。如果不指定这个选项,rm 会默默地删除文件 |
-r |
--recursive |
递归地删除文件,这意味着,如果要删除一个目录,而此目录又包含子目录,那么子目录也会被删除。要删除一个目录,必须指定这个选项。 |
-f |
--force |
忽视不存在的文件,不显示提示信息。这选项覆盖了--interactive选项。 |
-v |
--verbose |
显示详细的命令操作信息 |
类 Unix 系统,是没有复原命令的
当你使用带有通配符的rm命令时,除了仔细检查输入的内容外,先用ls命令来测试通配。
当你使用带有通配符的rm命令时,除了仔细检查输入的内容外,先用ls命令来测试通配。
当你使用带有通配符的rm命令时,除了仔细检查输入的内容外,先用ls命令来测试通配。
1 | rm *.html # 删除所有html文件 |
#创建链接
硬链接:
1 | ln file link |
符号链接:
1 | ln -s item link |
item可以是一个文件或是一个目录。
硬链接的缺点:
- 一个硬链接不能关联它所在文件系统之外的文件。这是说一个链接不能关联与链接本身不在同一个磁盘分区上的文件。
- 一个硬链接不能关联一个目录。
一个硬链接和文件本身没有什么区别。
当一个硬链接被删除时,这个链接被删除,但是文件本身的内容仍然存在,直到所有关联这个文件的链接都删除掉。
当你删除一个符号链接时,只有这个链接被删除,而不是文件自身。
如果先于符号链接删除文件,这个链接仍然存在,但是不指向任何东西。(会被 ls 命令标红,表示坏链接)
#测试
1 | onns@DESKTOP-5JJP7PL:~$ vi fun |
可以通过-i参数来展示文件索引节点的信息,可以看出这实际上是索引的同一个文件。
1 | onns@DESKTOP-5JJP7PL:~$ ln -s fun fun-sym |
符号链接的大小是指向文件字符的大小,而不是实际大小,因为fun-sym指向的是fun,fun有三个字符,所以大小是3。
对于符号链接,有一点值得记住,执行的大多数文件操作是针对链接的对象,而不是链接本身。
而rm命令是个特例。当你删除链接的时候,删除链接本身,而不是链接的对象。
#命令
四种命令的形式:
- 一个可执行程序
- 一个内建于
shell自身的命令,内部命令 - 一个
shell函数 - 一个命令别名
#type
type命令是shell内部命令,它会显示命令的类别:
1 | type command |
1 | onns@DESKTOP-5JJP7PL:~$ type type |
#which
which用来查找一个可执行程序的位置,因为一个程序可能有很多个版本:
1 | which command |
1 | onns@DESKTOP-5JJP7PL:~$ which ls |
这个命令只对可执行程序有效,不包括内建命令和命令别名。
第二个命令是我自己写的。
当我企图查找内部命令的时候,根本找不到= =,什么提示都没有:
1 | onns@DESKTOP-5JJP7PL:~$ which cd |
#help
help命令大概就是用来提示你这个命令怎么用的吧…
1 | help command |
1 | onns@DESKTOP-5JJP7PL:~$ help cd |
出现在命令语法说明中的方括号,表示可选的项目。
一个竖杠字符表示互斥选项。
虽
cd命令的帮助文档很简洁准确,但它决不是教程。[2]
--help是一个很多程序支持的选项,作用是:显示命令所支持的语法和选项说明。
1 | onns@DESKTOP-5JJP7PL:~$ mkdir --help |
#man
man命令用来查看一些程序的文档手册:
1 | man program |
手册文档的格式有点不同,一般地包含一个标题、命令语法的纲要、命令用途的说明、以及每个命令选项的列表和说明。手册文档通常并不包含实例。
在大多Linux系统中,man使less工具来显示参考手册,所以当浏览文档时,你所熟less悉命令都能有效。[3]
参考手册有很多不同的章节:
| 章节 | 内容 |
|---|---|
| 1 | 用户命令 |
| 2 | 程序接口内核系统调用 |
| 3 | C 库函数程序接口 |
| 4 | 特殊文件,比如说设备结点和驱动程序 |
| 5 | 文件格式 |
| 6 | 游戏娱乐,如屏幕保护程序 |
| 7 | 其他方面 |
| 8 | 系统管理员命令 |
有时候,我们需要查看参考手册的特定章节,从而找到我们需要的信息。如果我们要查找一种文件格式,而同时它也是一个命令名时, 这种情况尤其正确。没有指定章节号,我们总是得到第一个匹配项,可能在第一章节。我们这样使用man命令,来指定章节号:[4]
1 | man section search_term |
1 | onns@DESKTOP-5JJP7PL:~$ man 5 passwd |
#alias
alias用来创建别名,可以把多个命令放在同一行,命令之间用;分隔。
1 | alias name='command1; command2; command3...' |
在创建别名的时候,应该用type来测试一下这个别名有没有被用过。
删除别名,使用unalias命令。
在命令行里定义的别名,shell关闭之后就会消失。
#标准输入、输出和错误
Unix下万物皆文件,默认情况下,标准输出和标准错误都连接到屏幕,即stdout和stderr。标准输入连接到键盘上,即stdin。
#标准输出重定向
使用>重定向符后接文件名将标准输出重定向到除屏幕以外的另一个文件:
1 | command > filename |
1 | onns@DESKTOP-5JJP7PL:~$ ls -l /usr/bin > ls-output.txt |
1 | onns@DESKTOP-5JJP7PL:~$ ls -l /bin/usr > ls-output.txt |
ls程序不把它的错误信息输送到标准输出。
而且,当我们使用>重定向符来重定向输出结果时,目标文件总是从开头被重写。
快速清空一个文件内容或者创建一个新的空文件:
1 | > ls-output.txt |
使用>>操作符,将导致输出结果添加到文件内容之后,即追加。如果文件不存在,文件会被创建。
#标准错误重定向
stdin、stdout和stderr在shell内部被称为文件描述符0、1和2。
1 | ls -l /bin/usr 2> ls-error.txt |
2和>要紧挨着,不然会报错:
1 | onns@DESKTOP-5JJP7PL:~$ ls -l /bin/usr 2 > ls-error.txt |
如果想要把标准输出和标准错误一起重定向,有两种方法,老方法:
1 | ls -l /bin/usr > ls-output.txt 2>&1 |
标准错误的重定向必须总是出现在标准输出重定向之后。
1 | onns@DESKTOP-5JJP7PL:~$ ls -l /bin/usr > ls-output.txt # 错误还是会输出到标准输出 |
第二种方法是&>:
1 | onns@DESKTOP-5JJP7PL:~$ cat ls-output.txt |
/dev/null文件是系统设备,叫做位存储桶,它可以接受输入,并且对输入不做任何处理。
可以把不需要的东西输出给垃圾桶:
1 | ls -l /bin/usr 2> /dev/null |
#cat
cat命令读取一个或多个文件,然后复制它们到标准输出:
1 | cat [file] |
cat经常被用来显示简短的文本文件。
cat可以把多个分片的文件连在一起:
1 | cat movie.mpeg.0* > movie.mpeg |
因为通配符总是以有序的方式展开,所以这些参数会以正确顺序安排。
cat如果不加参数直接运行,将默认连接标准输入和标准输出。可以使用这种行为来创建简短的文本文件。
1 | onns@liupans-MacBook-Air ~ % cat > lazy_dog.txt |
输入Ctrl-d可以告诉cat已经到达文件末尾EOF。
#匿名管道
|可以让一个命令的标准输出通过管道送至另一个命令的标准输入。
1 | command1 | command2 |
#sort
1 | $ sort --help |
-b忽略每行前面开始出的空格字符。-c检查文件是否已经按照顺序排序。-d排序时,处理英文字母、数字及空格字符外,忽略其他的字符。-f排序时,将小写字母视为大写字母。-i排序时,除了 040 至 176 之间的 ASCII 字符外,忽略其他的字符。-m将几个排序好的文件进行合并。-M将前面 3 个字母依照月份的缩写进行排序。-n依照数值的大小排序。-u意味着是唯一的(unique),输出的结果是去完重了的。-o<输出文件> 将排序后的结果存入指定的文件。-r以相反的顺序来排序。-t<分隔字符>指定排序时所用的栏位分隔字符。+<起始栏位>-<结束栏位>以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。--help显示帮助。--version显示版本信息。
排序命令,默认是按照字典序排序。
#uniq
1 | $ uniq --help |
-c或--count在每列旁边显示该行重复出现的次数。-d或--repeated仅显示重复出现的行列。-f<栏位>或--skip-fields=<栏位>忽略比较指定的栏位。-s<字符位置>或--skip-chars=<字符位置>忽略比较指定的字符。-u或--unique仅显示出一次的行列。-w<字符位置>或--check-chars=<字符位置>指定要比较的字符。--help显示帮助。--version显示版本信息。[输入文件]指定已排序好的文本文件。如果不指定此项,则从标准读取数据;[输出文件]指定输出的文件。如果不指定此选项,则将内容显示到标准输出设备(显示终端)。
uniq从数据列表中删除任何重复行。
假设有如下文件:
1 | $ vi uniq-test |
执行uniq命令:
1 | $ uniq uniq-test |
当重复的行并不相邻时,uniq命令是不起作用的。
所以一般uniq之前先sort一下,这两个命令经常一起用。
1 | $ sort uniq-test | uniq |
#wc
1 | $ wc --help |
-c或--bytes或--chars只显示 Bytes 数。-l或--lines显示行数。-w或--words只显示字数。--help在线帮助。--version显示版本信息。
wc命令是用来显示文件所包含的行数、字数和字节数。
1 | $ wc ls-output.txt |
#grep
grep用来找到文件中的匹配文本:
1 | grep pattern [file...] |
比如用来查找名字里包含zip的命令:
1 | $ ls /bin /usr/bin | sort | uniq | grep zip |
-i使得 grep 在执行搜索时忽略大小写,-v选项会告诉 grep 只打印不匹配的行。
#head / tail
查看文件的头部/尾部。
-n来调整显示多少行。
因为有一些日志文件的尾部可能一直有更新,所以可以用-f选项一直把最新的尾部文件显示到屏幕上,用ctrl+c来停止监听。
#tee
tee程序从标准输入读入数据,并且同时复制数据到标准输出(允许数据继续随着管道线流动)和一个或多个文件。
用处是可以从一系列的管道中间读取数据到别的地方。(直观的想法就是,在管道上添加一个分支,私接水管(不是)
1 | $ ls /usr/bin | tee ls.txt | grep zip |
ls.txt里也有ls /usr.bin的数据:
1 | $ cat ls.txt | wc -l |
#字符展开
1 | echo * |
1 | $ echo * |
shell在echo命令被执行前把*展开成了另外的东西。
当回车键被按下时,shell在命令被执行前在命令行上自动展开任何符合条件的字符,所以echo命令的实际参数并不是*,而是它展开后的结果。
#路径名展开
通配符所依赖的工作机制叫做路径名展开。
1 | $ echo D* |
1 | $ echo *s |
1 | $ echo [[:upper:]]* |
1 | $ echo /usr/*/share |
以圆点字符开头的文件名是隐藏文件,路径名展开也尊重这种行为,echo *不会显示隐藏文件。
~当它用在一个单词的开头时,它会展开成指定用户的家目录名,如果没有指定用户名,则展开成当前用户的家目录:
1 | $ echo ~ |
如果有用户foo这个帐号,那么:
1 | $ echo ~foo |
#算术表达式展开
shell在展开中执行算数表达式,这允许我们把shell提示当作计算器来使用:
1 | $((expression)) |
1 | $ echo $((2*3)) |
算术表达式只支持整数。
然而我好像用了不是整数的数,也算出来结果了,可能和Linux版本有关系:
1 | $ echo $((5.2423/2)) |
支持的运算符:+ - * / % **。
因为只支持整数,所以除法的结果也是整数。
1 | $ echo $((5/2)) |
在算术表达式中空格并不重要,并且表达式可以嵌套。
1 | $ echo $(($((5**2)) * 3)) |
#花括号展开
可以从一个包含花括号的模式中创建多个文本字符串。
1 | $ echo Front-{A,B,C}-Back |
花括号展开模式可能包含一个开头部分叫做报头,一个结尾部分叫做附言。
花括号表达式本身可能包含一个由逗号分开的字符串列表,或者一个整数区间,或者单个的字符的区间。
这种模式不能嵌入空白字符。
1 | $ echo Number_{1..5} |
1 | $ echo {Z..A} |
花括号展开可以嵌套:
1 | $ echo a{A{1,2},B{3,4}}b |
还有一些参数变量展开:
1 | echo $USER |
但在参数展开中,如果你拼写错了一个变量名,展开仍然会进行,只是展开的结果是一个空字符串:
1 | echo $SUER |
#命令替换
命令替换允许我们把一个命令的输出作为一个展开模式来使用:
1 | $ echo $(ls) |
1 | $ ls -l $(which cp) |
1 | $ file $(ls /usr/bin/* | grep zip) |
在旧版shell程序中,有另一种语法也支持命令替换,使用倒引号来代替美元符号和括号:
1 | $ ls -l `which cp` |
#引用
用双引号包裹的字符串,单词分割、路径名展开、波浪线展开和花括号展开会失效,参数展开、 算术展开和命令替换仍然执行。
1 | $ echo "$USER $((2+2)) $(cal)" |
例外的是$ \ `。
在默认情况下,单词分割机制会在单词中寻找空格,制表符,和换行符,并把它们看作单词之间的界定符。这意味着无引用的空格,制表符和换行符都不是文本的一部分,它们只作为分隔符使用。
虽然命令替换还有效果,但是有时候可能会有用:
1 | $ echo $(cal) |
如果需要禁止所有的展开,我们要使用单引号。
1 | $ echo '$USER $((2+2)) $(cal)' |
也可以用单个的转义字符反斜杠\。
注意在单引号中,反斜杠失去它的特殊含义,它被看作普通字符。
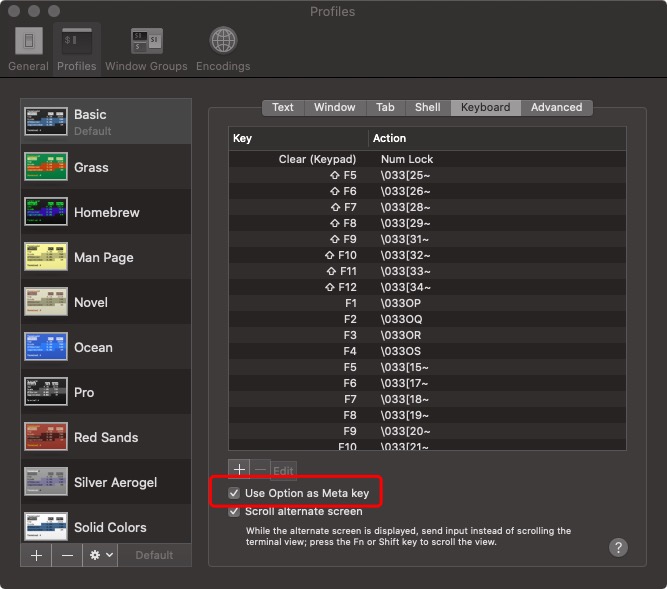
#恢复 alt 键功能
在MacOS的Terminal里,用alt组合键总是不好使,这次查了一下,问题解决。
Terminal -> Preferences(快捷键cmd + ,) -> Profiles -> Keyboard -> Use Option as Meta key
#参考链接
#移动光标
| 按键 | 效果 |
|---|---|
Ctrl-a |
移动光标到行首。 |
Ctrl-e |
移动光标到行尾。 |
Ctrl-f |
光标后移一个字符 |
Ctrl-b |
光标前移一个字符 |
Alt-f |
光标后移一个字。 |
Alt-b |
光标前移一个字。 |
Ctrl-l |
清空屏幕,移动光标到左上角。 |
#修改文本
| 按键 | 效果 |
|---|---|
Ctrl-d |
删除光标位置的字符。 |
Ctrl-t |
光标位置的字符和光标前面的字符互换位置。 |
Alt-t |
光标位置的字和其前面的字互换位置。 |
Alt-l |
把从光标位置到字尾的字符转换成小写字母。 |
Alt-u |
把从光标位置到字尾的字符转换成大写字母。 |
ctrl + t这个很有用,因为其实经常都是打反两个字母,比如我,经常把conda activate打成conda acitvate。但是我在macOS上测试的时候,确实是光标位置的字符和光标前面的字符互换位置,但是换位完之后,光标往后挪了一个位置(如果后面还有文本的话)。
#剪切粘贴
Readline的文档使用术语 killing 和 yanking 来指我们平常所说的剪切和粘贴。剪切下来的本文被存储在一个叫做剪切环(kill-ring)的缓冲区中。
| 按键 | 效果 |
|---|---|
Ctrl-k |
剪切从光标位置到行尾的文本。 |
Ctrl-u |
剪切从光标位置到行首的文本。 |
Alt-d |
剪切从光标位置到词尾的文本。 |
Alt-Backspace |
剪切从光标位置到词头的文本。如果光标在一个单词的开头,剪切前一个单词。 |
Ctrl-y |
把剪切环中的文本粘贴到光标位置。 |
Alt-Backspace如果光标在一个单词的开头,剪切前一个单词,同时会把两个词之间的空格也一起剪切掉并且存在剪切环里。
#自动补全
| 按键 | 效果 |
|---|---|
Alt-? |
显示可能的自动补全列表。 |
Alt-* |
插入所有可能的自动补全。 |
alt + ?等效于tab两次。
这俩命令我试不出来。。好在目前也没什么用= =!
#历史命令
bash维护着一个已经执行过的命令的历史列表。这个命令列表被保存在你家目录下,一个叫做.bash_history的文件里。
在默认情况下,bash 会存储你所输入的最后 500 个命令。
每个历史记录都有行号,我们可以使用一种叫做历史命令展开的方式,来调用行号所代表的这一行命令:
1 | !line-number |
1 | $ history |
bash也具有增量搜索历史列表的能力。
输入 Ctrl-r 来启动增量搜索,接着输入你要寻找的字。当你找到它以后,你可以敲入 Enter 来执行命令,或者输入 Ctrl-j,从历史列表中复制这一行到当前命令行。再次输入 Ctrl-r,来找到下一个匹配项(历史列表中向上移动)。输入 Ctrl-g 或者 Ctrl-c,退出搜索。
1 | $ |
1 | $ uniq --help |
说实话,好麻烦,我还是喜欢用grep + 管道。
| 按键 | 效果 |
|---|---|
Ctrl-p |
移动到上一个历史条目。类似于上箭头按键。 |
Ctrl-n |
移动到下一个历史条目。类似于下箭头按键。 |
Alt-< |
移动到历史列表开头。 |
Alt-> |
移动到历史列表结尾,即当前命令行。 |
Ctrl-r |
反向增量搜索。从当前命令行开始,向上增量搜索。 |
Alt-p |
反向搜索,非增量搜索。(输入要查找的字符串,按下 Enter 来执行搜索)。 |
Alt-n |
向前搜索,非增量。 |
Ctrl-o |
执行历史列表中的当前项,并移到下一个。如果你想要执行 历史列表中一系列的命令,这很方便。 |
历史命令展开:
| 按键 | 效果 |
|---|---|
!! |
重复最后一次执行的命令。可能按下上箭头按键和 enter 键 更容易些。 |
!number |
重复历史列表中第 number 行的命令。 |
!string |
重复最近历史列表中,以这个字符串开头的命令。 |
!?string |
重复最近历史列表中,包含这个字符串的命令。 |
应该小心谨慎地使用 !string 和 !?string 格式,除非你完全确信历史列表条目的内容。
#用户
当一个用户拥有一个文件或目录时,用户对这个文件或目录的访问权限拥有控制权。
1 | $ id |
对于文件和目录的访问权力是根据读访问、写访问和执行访问来定义的。
1 | $ > foo.txt |
列表的前十个字符是文件的属性,第一个字符表明文件类型。
| 按键 | 效果 |
|---|---|
- |
一个普通文件 |
d |
一个目录 |
l |
一个符号链接[5] |
c |
一个字符设备文件[6] |
b |
一个块设备文件[7] |
剩下的九个字符叫做文件模式,代表着文件所有者、文件组所有者和其他人的读、写和执行权限。
文件:
r:允许打开并读取文件内容。w:允许写入文件内容或截断文件。但是不允许对文件进行重命名或删除,重命名或删除是由目录的属性决定的。x:允许将文件作为程序来执行,使用脚本语言编写的程序必须设置为可读才能被执行。
目录:
r:允许列出目录中的内容,前提是目录必须设置了可执行属性(x)。w:允许在目录下新建、删除或重命名文件,前提是目录必须设置了可执行属性(x)。x:允许进入目录,例如:cd directory。
#chmod
只有文件的所有者或者超级用户才能更改文件或目录的模式。
chmod命令支持两种不同的方法来改变文件模式:八进制数字表示法或符号表示法。
| 八进制 | 二进制 | 文件模式 |
|---|---|---|
0 |
000 |
--- |
1 |
001 |
--x |
2 |
010 |
-w- |
3 |
011 |
-wx |
4 |
100 |
r-- |
5 |
101 |
r-x |
6 |
110 |
rw- |
7 |
111 |
rwx |
常用权限:7 (rwx),6 (rw-),5 (r-x),4 (r--),和 0 (-–)。
| 符号 | 解释 |
|---|---|
u |
user的简写,意思是文件或目录的所有者。 |
g |
groups的简写,用户组。 |
o |
others的简写,意思是其他所有的人。 |
a |
all的简写,是u、g和o三者的联合。 |
如果没有指定字符,则假定使用all。
权限操作:
+:加上一个权限。-:删掉一个权限。=:只有指定的权限可用,其它所有的权限被删除。
多种设定可以用逗号分开。
u+x,go=rw:给文件拥有者执行权限并给组和其他人读和执行的权限。
#umask
当创建一个文件时,umask命令控制着文件的默认权限。
umask以掩码的形式来工作,和网关那里差不多,一般是022和002。
比如说正常一个权限是666(110 110 110),即rw-rw-rw-,被022(000 010 010)的umask后会变成110 100 100,即644,rw-r--r--。
虽然我们通常看到一个八进制的权限掩码用三位数字来表示,但是从技术层面上来讲,用四位数字来表示它更确切些。为什么呢?因为除了读取、写入和执行权限之外,还有其它较少用到的权限设置。
其中之一是 setuid 位(八进制 4000)。当应用到一个可执行文件时,它把有效用户 ID 从真正的用户(实际运行程序的用户)设置成程序所有者的 ID。这种操作通常会应用到一些由超级用户所拥有的程序。当一个普通用户运行一个程序,这个程序由根用户 (root) 所有,并且设置了 setuid 位,这个程序运行时具有超级用户的特权,这样程序就可以访问普通用户禁止访问的文件和目录。很明显,因为这会引起安全方面的问题,所有可以设置 setuid 位的程序个数,必须控制在绝对小的范围内。
第二个是 setgid 位(八进制 2000),这个相似于 setuid 位,把有效用户组 ID 从真正的用户组 ID 更改为文件所有者的组 ID。如果设置了一个目录的 setgid 位,则目录中新创建的文件具有这个目录用户组的所有权,而不是文件创建者所属用户组的所有权。对于共享目录来说,当一个普通用户组中的成员,需要访问共享目录中的所有文件,而不管文件所有者的主用户组时,那么设置 setgid 位很有用处。
第三个是 sticky 位(八进制 1000)。这个继承于 Unix,在 Unix 中,它可能把一个可执行文件标志为“不可交换的”。在 Linux 中,会忽略文件的 sticky 位,但是如果一个目录设置了 sticky 位,那么它能阻止用户删除或重命名文件,除非用户是这个目录的所有者,或者是文件所有者,或是超级用户。这个经常用来控制访问共享目录,比方说/tmp。
每个命令还是要给个例子,我tee命令虽然知道是怎么工作的,但是用的时候还是自然而然的加了一个>,错了= =。
#su
1 | su [-[l]] [user] |
如果包含-l选项,那么会为指定用户启动一个需要登录的shell,如果不指定用户,那么就假定是超级用户。
-l可以缩写为-:
1 | deploy@iZwz96txzmeg2f5wu9eqigZ:~$ su - |
也可以只执行单个命令,而不是启动一个新的可交互的 shell:
1 | su -c 'command' |
单引号保证了不会有任何展开。
1 | $ su -c 'ls -l /root/*' |
#sudo
管理员能够配置sudo命令,从而允许一个普通用户以不同的身份(通常是超级用户),通过一种非常可控的方式来执行命令。尤其是,只有一个用户可以执行一个或多个特殊命令时。
sudo命令不要求超级用户的密码,而是使用自己的密码来认证。
su 和 sudo 之间的一个重要区别是 sudo 不会重新启动一个 shell,也不会加载另一个用户的 shell 运行环境。这意味者命令不必用单引号引起来。
几年前,大多数的 Linux 发行版都依赖于 su 命令,来达到目的。su 命令不需要 sudo 命令所要求的配置,su 命令拥有一个 root 帐号,是 Unix 中的传统。但这会引起问题。所有用户会企图以 root 用户帐号来操纵系统。事实上,一些用户专门以 root 用户帐号来操作系统,因为这样做,的确消除了所有那些讨厌的“权限被拒绝” 的消息。你这样做就会使得 Linux 系统的安全性能被降低到和 Windows 系统相同 的级别。不是一个好主意。
当引进 Ubuntu 的时候,它的创作者们采取了不同的策略。默认情况下,Ubuntu 不允许用户登录到 root 帐号(因为不能为 root 帐号设置密码),而是使用 sudo 命 令授予普通用户超级用户权限。通过 sudo 命令,最初的用户可以拥有超级用户权 限,也可以授予随后的用户帐号相似的权力。
#chown
chown命令被用来更改文件或目录的所有者和用户组。使用这个命令需要超级用户权限。
1 | chown [owner][:[group]] file... |
bob: 把文件所有者从当前属主更改为用户 bob。
bob:users: 把文件所有者改为用户 bob,文件用户组改为用户组 users。
:admins: 把文件用户组改为组 admins,文件所有者不变。
bob:: 文件所有者改为用户 bob,文件用户组改为用户 bob 登录 系统时所属的用户组。
在大多数的配置中,sudo 命令会相信你几分钟,直到计时结束。
#chgrp
在旧版 Unix 系统中,chown 命令只能更改文件所有权,而不是用户组所有权。为了达到目的, 使用一个独立的命令,chgrp 来完成。除了限制多一点之外,chgrp 命令与 chown 命令使用起 来很相似。
#passwd
设置或更改用户密码:
1 | passwd [user] |
当系统启动的时候,内核先把一些它自己的活动初始化为进程,然后运行一个叫做 init 的程 序。init,依次地,再运行一系列的称为 init 脚本的 shell 脚本(位于/etc),它们可以启动所有 的系统服务。其中许多系统服务以守护(daemon)程序的形式实现,守护程序仅在后台运行,没有任何用户接口 (User Interface)。这样,即使我们没有登录系统,至少系统也在忙于执行一 些例行事务。[8]
在进程方案中,一个程序可以发动另一个程序被表述为一个父进程可以产生一个子进程。
内核维护每个进程的信息,以此来保持事情有序。例如,系统分配给每个进程一个数字,这 个数字叫做进程 (process) ID 或 PID。PID 号按升序分配,init 进程的 PID 总是 1。内核也对 分配给每个进程的内存和就绪状态进行跟踪以便继续执行这个进程。
#ps
ps全称process status。
1 | $ ps |
默认情况下,ps 不会显示很多进程信息,只是列出与当前终端会话相关的进程。
TTY 是 “Teletype”(直译电传打字机) 的简写,是指进程的控制终端。
TIME 字段表示进程所消耗的 CPU 时间数量。
加上 x 选项,告诉 ps 命令,展示所有进程,不管它们由什么终端(如果有的话)控制。
在 TTY 一栏中出现的?,表示没有控制终端。
1 | $ ps x |
输出结果中,新添加了一栏,标题为 STAT。 STAT 是 “state” 的简写,它揭示了进程当前状态:
R: 运行中。这意味着,进程正在运行或准备运行。
S: 正在睡眠。进程没有运行,而是,正在等待一个事件,比如 说,一个按键或者网络分组。
D: 不可中断睡眠。进程正在等待 I/O,比方说,一个磁盘驱动 器的 I/O。
T: 已停止. 已经指示进程停止运行。稍后介绍更多。
Z: 一个死进程或“僵尸”进程。这是一个已经终止的子进程, 但是它的父进程还没有清空它。(父进程没有把子进程从进程表中删除)
<: 一个高优先级进程。这可能会授予一个进程更多重要的资 源,给它更多的 CPU 时间。进程的这种属性叫做 niceness。 具有高优先级的进程据说是不好的(less nice),因为它占用了比较多的 CPU 时间,这样就给其它进程留下很少时间。
N: 低优先级进程。一个低优先级进程(一个“nice”进程)只有 当其它高优先级进程被服务了之后,才会得到处理器时间。
不过我的系统里有Ss和R+之类的,在书里没有。
还有一个选项aux:
1 | USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND |
USER: 用户 ID. 进程的所有者。
%CPU: 以百分比表示的 CPU 使用率。
%MEM: 以百分比表示的内存使用率。
VSZ: 虚拟内存大小。
RSS: 进程占用的物理内存的大小,以千字节为单位。
START: 进程启动的时间。若它的值超过 24 小时,则用天表示。
#top
默认情况下,top每三秒钟更新一次。
1 | top - 19:25:51 up 170 days, 1:13, 1 user, load average: 0.00, 0.00, 0.00 |
top:程序名。
19:25:51:当前时间。
up 170 days, 1:13:这是正常运行时间。它是计算机从上次启动到现在所运行的时间。
1 user:登录系统用户数。
load average: 0.00, 0.00, 0.00:加载平均值。等待运行的进程数目,也就是说,处于可以运行状态并共享 CPU 的进程个数。第一个是最后 60 秒的平均值,下一个是前 5 分钟的平均值,最后一个是前 15 分钟的平均值。若平均值低于1.0,则指示计算机工作不忙碌。
Tasks:总结了进程数目和这些进程的各种状态。
Cpu(s):描述了 CPU 正在进行的活动的特性。
us:用户进程。
sy:系统(内核)进程。
ni:nice(低优先级)进程。
id:CPU空闲率。
wa:等待I/O。
hi:硬件中断。
si:软件中断。
st:cpu cycle 被虚拟化偷走的比例。
Mem:物理内存的使用情况。
Swap:交换分区(虚拟内存)的使用情况。
h命令显示帮助。
q退出top命令。
#&
在命令后加&后台执行:
1 | command & |

这个xlogo命令可以在显示屏上显示一个X,可以随着拖动变大小,必须要有显示器才行。
#&
在命令后加&后台执行:
1 | command & |
1 | onns@onns-desktop:~$ xlogo & |
[1] 3642是 shell 特性的一部分,叫做任务控制(job control)。
任务号(job number)为1,PID 为3642。
1 | onns@onns-desktop:~$ ps |
jobs命令列出从终端中启动了的任务:
1 | onns@onns-desktop:~$ jobs |
#fg
fg命令让一个进程返回前台:
1 | fg %jobspec |
fg命令之后接一个百分号和任务序号(jobspec)。
如果只有一个后台任务,那么jobspec(job specification)是可有可无的。
1 | onns@onns-desktop:~$ jobs |
#ctrl z
停止进程,这么做通常是为了允许前台进程被移动到后台。
1 | onns@onns-desktop:~$ xlogo |
使用 fg 命令,可以恢复程序到前台运行,或者用 bg 命令把程序移到后台。
1 | onns@onns-desktop:~$ bg %2 |
#kill
kill命令用来终止程序。
这个
kill命令不是真的“杀死”程序,而是给程序发送信号。信号是操作系统与程序之间进行通信时所采用的几种方式中的一种。
1 | kill [-signal] PID... |
如果在命令行中没有指定信号,那么默认情况下,发送TERM(Terminate,终止)信号。
- 编号
1代表HUP,挂起(Hangup)。这是美好往昔的残留部分,那时候终端机通过电话线和调制解调器连接到远端的计算机。这个信号被用来告诉程序,控制的终端机已经“挂断”。通过关闭一个终端会话,可以展示这个信号的作用。在当前终端运行的前台程序将会收到这个信号并终止。许多守护进程也使用这个信号,来重新初始化。这意味着,当一个守护进程收到这个信号后,这个进 程会重新启动,并且重新读取它的配置文件。Apache 网络服务器守护进程就是一个例子。 - 编号
2代表INT,中断。实现和 Ctrl-c 一样的功能,由终端发送。通常, 它会终止一个程序。 - 编号
9代表KILL,杀死。这个信号很特别。尽管程序可能会选择不同的 方式来处理发送给它的信号,其中也包含忽略信号, 但是 KILL 信号从不被发送到目标程序。而是内核立 即终止这个进程。当一个进程以这种方式终止的时候, 它没有机会去做些“清理”工作,或者是保存工作。 因为这个原因,把 KILL 信号看作最后一招,当其它 终止信号失败后,再使用它。 - 编号
15代表TERM,终止。这是 kill 命令发送的默认信号。如果程序仍然 “活着”,可以接受信号,那么这个它会终止。 - 编号
18代表CONT,继续。在一个停止信号后,这个信号会恢复进程的运 行。 - 编号
19代表STOP,停止。这个信号导致进程停止运行,而不是终止。像 KILL 信号,它不被发送到目标进程,因此它不能被忽略。
进程,和文件一样,拥有所有者,所以为了能够通过 kill 命令来给进程发送信号,你必须是 进程的所有者(或者是超级用户)。
kill -l可以得到一个完整的信号列表:
1 | onns@onns-desktop:~$ kill -l |
不是很常用,蛮看一下罢了。
#printenv
printenv程序用来查看环境变量。
不知道为什么我的set命令输出的是一堆奇怪的东西= =。
别名无法通过使用set或printenv来查看。
用不带参数的`alias 来查看别名:
1 | $ alias |
#vi
vi启动后会直接进入命令模式。
按下i键进入插入模式:
1 | -- INSERT -- |
按下w键保存修改内容。
按下q键退出。
vi中的许多命令都可以在前面加上一个数字。
19:16,今天先看到这里吧!看了很多但值得整理的蛮少的。