当前工作进度报告
| 2020-12-27 | 中期进展报告 | 刘潘 |
|---|
#综述
当前行为识别的主流方向有两个,分别是双流二维卷积神经网络和三维卷积神经网络。
随着数据集大小的增加和部署需求的增加,效率成为一个重要的关注点。
如果我们使用基于双流网络的方法,我们需要预先计算光流并存储在本地磁盘上。以Kinetics-400数据集为例,存储所有光流图像需要 4.5TB 的磁盘空间。如此庞大的数据量将使 I/O 成为训练过程中最紧张的瓶颈,导致 GPU 资源的浪费和实验周期的延长。此外,预计算光流并不便宜,这意味着所有的双流网络方法都不是实时的。
如果我们使用基于 3D cnn 的方法,人们仍然发现 3D cnn 训练困难,部署具有挑战性。在训练方面,使用高端 8-GPU 机器在 Kinetics400 数据集上训练一个标准的Slow-Fast网络需要 10 天才能完成。如此漫长的实验周期和巨大的计算成本,使得视频理解研究只能面向拥有丰富计算资源的大公司/实验室。最近有几项科研成果尝试加速深度视频模型的训练,但与大多数基于图像的计算机视觉任务相比,这些仍然是昂贵的。在部署方面,3D 卷积在不同平台上的支持不如 2D 卷积,3D cnn 需要更多的视频帧作为输入,增加了额外的 IO 成本。
上述问题的一个可行的解决方案是用一种近似光流的手段来代替光流,从而让模型有能够具备高效推理的潜力来应用到实时检测领域中。
#多尺度边缘表征双流网络
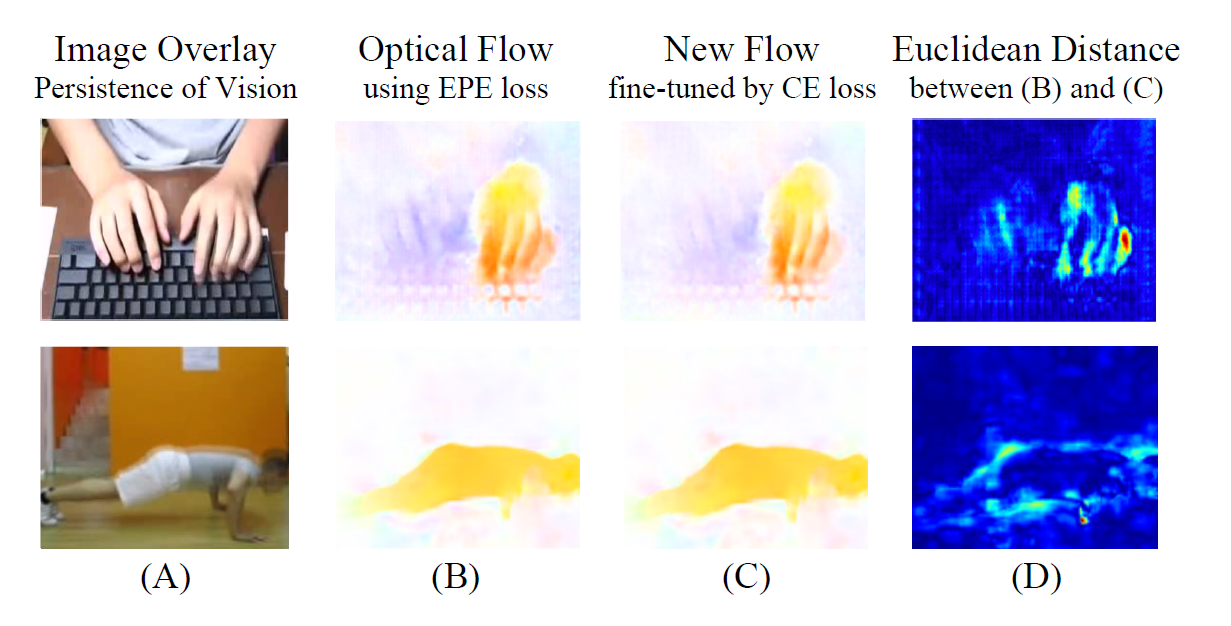
图 B 是通过 EPE loss 得到的光流图像[1],图 C 是通过将光流网络和分类网络融合后训练得到的微调光流图像,后者在分类准确率上具有更好的效果。
通过可视化图 B 和图 C 之间的差距,可以看出运动的边界对于运动的表示起到了很重要的作用,故可以用图像边缘的运动来作为光流的一种替代方案。
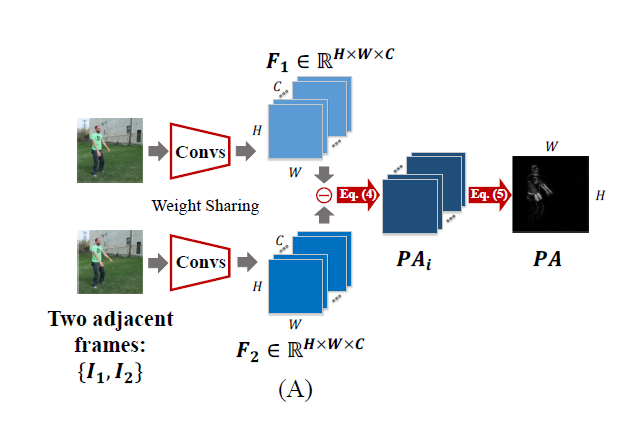
给定相邻帧的输入,首先通过一个卷积神经网络来提取边缘特征,然后通过计算边缘的差异来表征运动信息,作为双流输入中的“光流”分支。
#多尺度运动边缘表征
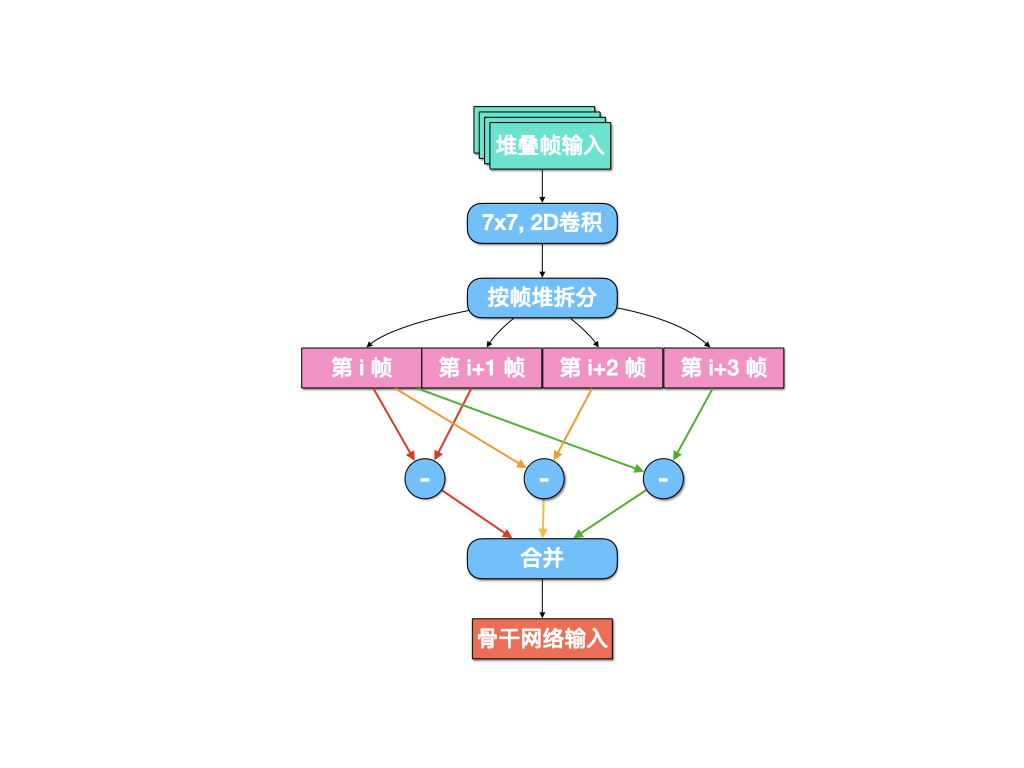
在实际的运动表征中,会出现相邻两帧之间的运动幅度非常小的情况,而单纯增加采样间隔也会对那些相邻两帧之间变化大的视频造成影响,同时也难以对帧数较少的视频进行描述,故采用一种多尺度的运动边缘表征作为网络的输入。
#多通道信息融合
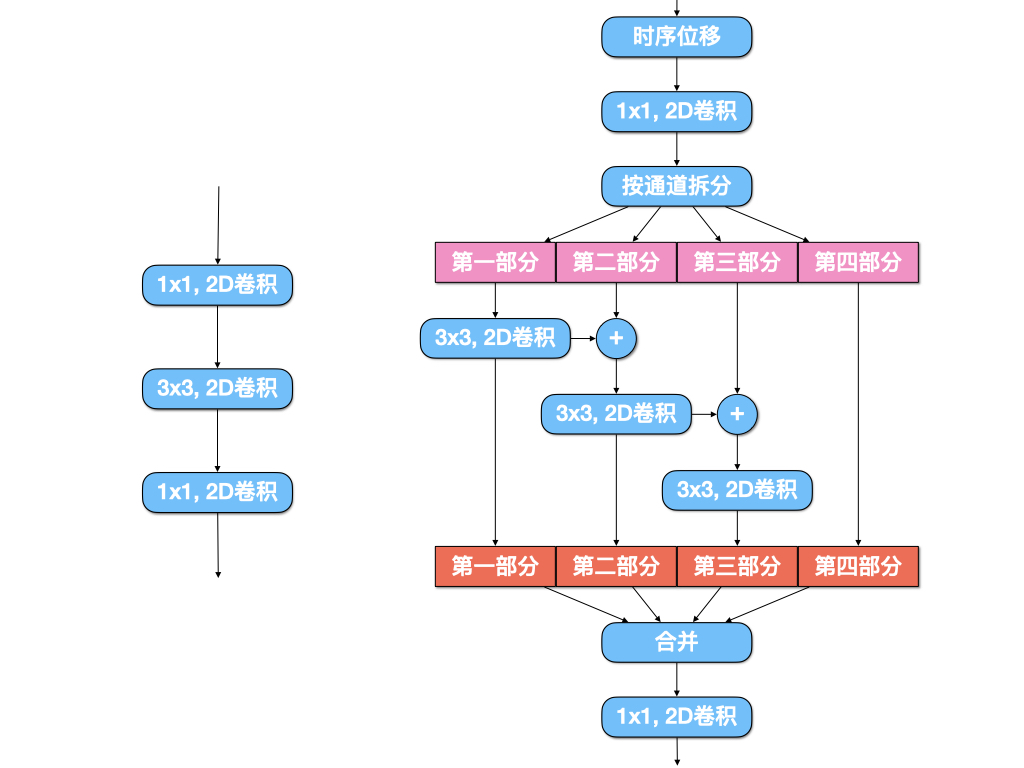
#数据增强
由于视频数据的特殊性,一些常用的对于图像输入的数据增强操作都难以应用到视频输入中,除此之外,对于定义“喝水”、“骑自行车”等特定动作的数据集而言,依然可以通过水平翻转这类型的数据增强手段,但对于Something-Something这类数据集而言,“把物体从左侧拿到右侧”的水平翻转就会影响到最终的实验结果。故在此数据集上能够加入的数据增强操作仅仅只有尺度抖动,即:
1 | GroupMultiScaleCrop(self.input_size, [1, .875, .75, .66]) |
既然时序信息在行为识别的分类上起到了非常重要的作用,一个可能的数据增强手段是将视频的帧逆序输入作为一个新的分支,最后双流分支中的动作分支结果由两个时序分支结果加权得到。
| No | Method | Backbone | Frame | FLOPs × views | Val Top1 | Val Top5 |
|---|---|---|---|---|---|---|
| 1 | Baseline | - | 8+8×4 | 67.7G × 1 | 50.5 | 79.2 |
| 2 | + reverse | - | 8+8×4 | - | 51.54 | 79.86 |
#实验结果
| No | Method | Backbone | Frame | FLOPs × views | Val Top1 | Val Top5 |
|---|---|---|---|---|---|---|
| 1 | Baseline | - | 8+8×4 | 67.7G × 1 | 50.5 | 79.2 |
| 2 | + ms | - | 8+8×4 | - | 50.72 | 79.48 |
| 3 | + mc | - | 8+8×4 | - | 51.93 | 80.15 |
| 4 | + ms + mc | - | 8+8×4 | - | 52.44 | 80.35 |
| 5 | Baseline | - | (8+8×4)x2 | (46.6G+88.4G) x 2 | 53.4 | 81.1 |
| 6 | + ms | - | (8+8×4)x2 | - | 53.77 | 81.43 |
| 7 | + ms + mc | - | (8+8×4)x2 | - | 54.80 | 82.55 |
EPE 是一种对光流预测错误率的一种评估方式。指所有像素点的 gound truth 和预测出来的光流之间差别距离(欧氏距离)的平均值。 ↩︎