A Comprehensive Study of Deep Video Action Recognition
Contents
#A Comprehensive Study of Deep Video Action Recognition
2020 年 12 月的新论文,亚马逊李沐团队提出,行为识别的全面调研(2014-2020)。
最近十年的数据集:

行为识别研究分为三个大体的趋势:
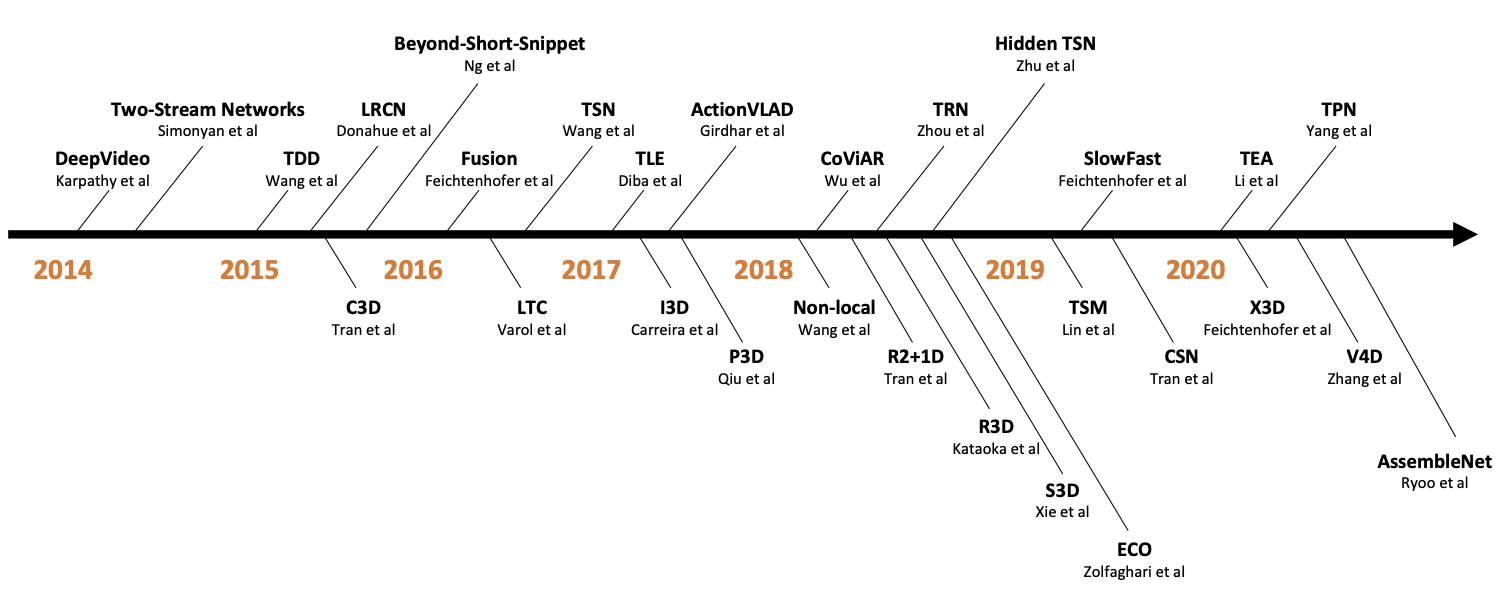
上方的双流/2D 卷积和下方的 3D 卷积。
还有一条隐藏的线是提高计算效率,使之适用于更大的数据集,从而在实际应用中得到应用。
UCF101和Kinetics400基本上可以通过场景和内容来推断出分类结果。
Something-Something数据集需要强大的时间建模,因为大多数活动不能仅基于空间特征来推断。该数据集中于人与对象的交互,因此它更细粒度,需要强大的时间建模。
#挑战
从数据集角度,为训练行为识别的模型定义标签空间是一项很大的挑战,因为一项动作可能由不同的人会由不同的定义(比如拿起杯子和喝水)。除此之前,对视频进行的行为进行标注是费力的(你必须观看所有的帧)和模糊的(一个动作什么时候酸结束,这个是很难定义的)。还有一个原因,像Kinetics数据集只给了视频链接,其中很大一部分的数据已经被删除或者不可访问,大家很难在同一个基准上做实验。
从建模角度,人类的行为动作具有很强的类内和类间差异,第二,识别人类行为需要同时理解短期特定动作的运动信息和长期时间信息。第三,训练和推理的计算成本都很高,阻碍了动作识别模型的开发和部署。
#史诗
所有的故事都会是从DT和iDT开始讲,但是它的缺点:手工制作的特性计算成本很高,而且难以扩展和部署。
DeepVideo算是这一派的开山祖师,不过效果并不如上面说的手工设计的特征(在UCF101数据集上 65.4% vs 87.9%)。不过DeepVideo发现,一个由单个视频帧所训练的网络,在输入被改变为一组帧时,同样表现良好。这其实表明其实网络并没有很好得捕捉动作信息。这其实也鼓励人们思考,为什么卷积神经网络模型不像其他计算机视觉任务一样,在视频领域的表现没有超过传统手工制作的特征。
#Two-stream networks
由于视频的直观理解需要运动信息,寻找合适的方式来描述帧间的时间关系对于提高基于卷积神经网络的视频动作识别的性能至关重要。
与使用原始 RGB 图像作为输入相比,光流可以有效地去除静止背景,从而使学习问题更加简单。
双流法得出了两个重要的结论:
- 运动信息是视频动作识别的重要内容。
- 对于 CNN 来说,直接从原始视频帧中学习时间信息仍然具有挑战性。
因为在一个双流网络中有两个流。将会有一个阶段,需要合并两个网络的结果,以获得最终的预测。这一阶段通常称为时空融合步骤。
最简单、最直接的方法是late fusion。它对来自两个信息流的预测进行加权平均。尽管后期融合被广泛采用,但许多研究人员认为,这可能不是融合空间外观流和时间运动流信息的最佳方式。他们相信,在模型学习过程中,两个网络之间早期的互动可以使两个流都受益,这被称为早期融合,即early fusion。
(20201227 更新:LSTM 我一窍不通,所以省略)
#基于分段的方法
TSN在每个片段中随机选择一个视频帧,最后,分段一致性被执行以聚合来自采样视频帧的信息。TSN能够对长期时间结构进行建模,因为模型可以看到整个视频的内容。此外,这种稀疏采样策略降低了长视频序列的训练成本,但保留了相关信息。
#多流网络
双流网络之所以成功,是因为视频的外观和运动信息是两个最重要的属性。但还有一些其它的对行为识别有帮助的信息,比如姿态、物体、声音或者深度信息等。
#三维卷积神经网络
C3D在标准基准上的性能并不令人满意,但显示出很强的泛化能力,可以作为各种视频任务的通用特征提取器。
然而,3D 网络很难优化。为了更好地训练一个 3D 卷积滤波器,人们需要一个包含不同视频内容和动作类别的大规模数据集。
然而,C3D 的训练需要几周的时间来收敛。尽管 C3D 很受欢迎,但大多数用户只是将其作为不同用例的特征提取器,而不是修改/微调网络。
I3D改变了这一现象,它的主要贡献点有两个:
- 用成熟的图像分类体系用于 3D CNN。
- 对于模型权值,采用【Towards Good Practices for Very Deep Two-Stream ConvNets】中初始化光流网络的方法,将 ImageNet 预先训练好的 2D 模型权值膨胀到 3D 模型中的对应模型。
三维卷积神经网络并不会取代双流网络,它们也不是相互排斥的。
#统一二维和三维卷积神经网络
P3D和R2+1D 都是把3x3x3的卷积核替换成了3x1x1和1x3x3的卷积核来减少计算量。
除此之外还有别的方法直接将2D和3D卷积在一个网络里进行了混合。
在网络的底部使用二维卷积核替代三维卷积核,发现这种头重脚轻的网络具有更高的识别精度。
(non-local是区别于卷积核卷局部的概念而提出的,但是这个方向我没有研究,所以也略过。)
#提升三维卷积的效率
随着高效 2D 网络的发展,研究者们开始采用基于信道的可分卷积,并将其扩展到视频分类中。
#高效视频建模
随着数据集大小的增加和部署需求的增加,效率成为一个重要的关注点。如果我们使用基于双流网络的方法,我们需要预先计算光流并存储在本地磁盘上。以Kinetics-400数据集为例,存储所有光流图像需要 4.5TB 的磁盘空间。如此庞大的数据量将使 I/O 成为训练过程中最紧张的瓶颈,导致 GPU 资源的浪费和实验周期的延长。此外。预计算光流并不便宜,这意味着所有的双流网络方法都不是实时的。
如果我们使用基于 3D cnn 的方法,人们仍然发现 3D cnn 训练困难,部署具有挑战性。在训练方面,使用高端 8-GPU 机器在 Kinetics400 数据集上训练一个标准的Slow-Fast网络需要 10 天才能完成。如此漫长的实验周期和巨大的计算成本,使得视频理解研究只能面向拥有丰富计算资源的大公司/实验室。最近有几次尝试加速深度视频模型的训练,但与大多数基于图像的计算机视觉任务相比,这些仍然是昂贵的。
在部署方面,3D 卷积在不同平台上的支持不如 2D 卷积,3D cnn 需要更多的视频帧作为输入,增加了额外的 IO 成本。
#类光流算法
双流网络的一个主要缺点是对光流的需求。预计算光流的计算成本高,存储要求高,而且不能对视频动作识别进行端到端训练。如果我们能找到一种不用光流来编码运动信息的方法,那将是很有吸引力的。至少在推理时间。
PAN通过计算连续特征图之间的差异。
#未来研究方向
- 模型分析和可视化
- 数据增强
- 视频领域自适应(迁移学习)
- 神经结构搜索
- 高效的模型开发
- 新数据集
- 视频对抗攻击
- 零样本动作识别
- 弱监督的视频动作识别
- 细粒度视频动作识别
- 以自我为中心的行为识别
- 多模态
- 自监督视频表示学习