周报-20201008
Contents
| 2020-10-08 | 周报#07 | 刘潘 |
|---|
#I. Task achieved last week
- 找到合适的 Latex 毕设模板,并且成功的编译,开始写论文的摘要部分。
- 《TEA: Temporal Excitation and Aggregation for Action Recognition》
- 修改了现有代码,等待实验结果。
#II. Reports
#Latex 模板
找了一个比较新的厦门大学研究生学位论文 LaTeX 模板模板:https://github.com/zoam/xmu-thesis-grd,自己修改了一些特性。
#TEA: Temporal Excitation and Aggregation for Action Recognition
#问题提出
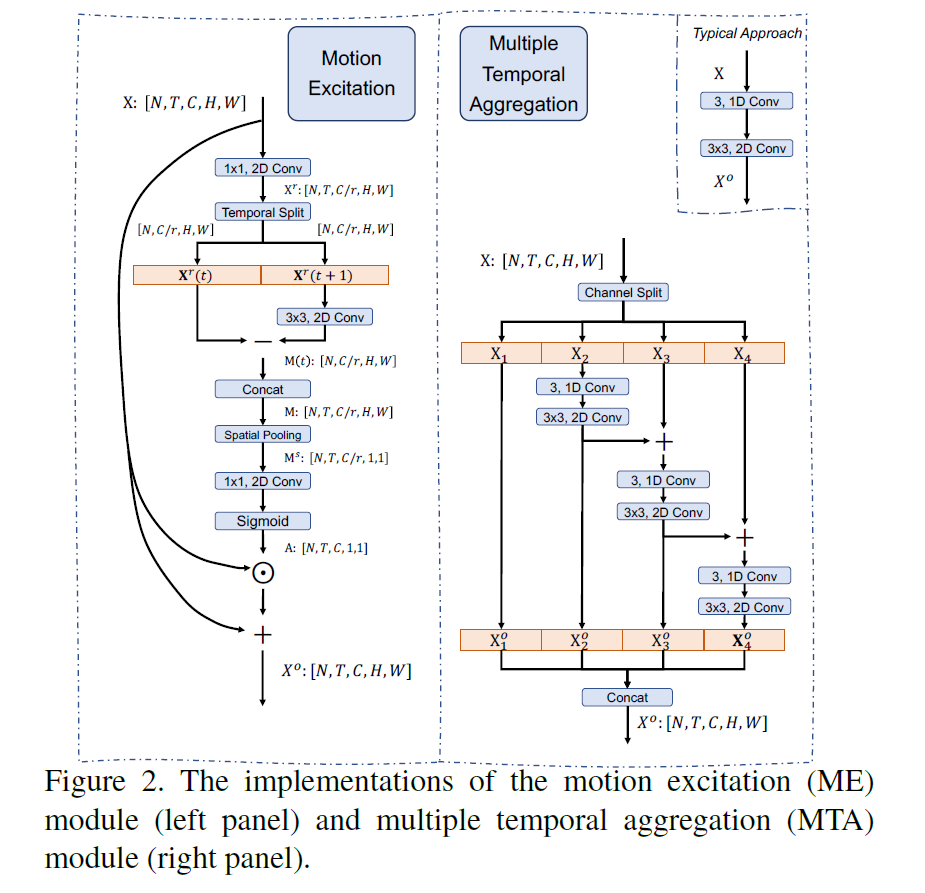
时序建模的两个问题:short-range motion encoding和long-range temporal aggregation。
前者基本依赖光流来解决,因为计算量很大,且无法满足实时的任务,所以作者提出motion excitation。
后者现有的解决方案有两个:
- adopt 2D CNN backbones to extract frame-wise features and then utilize a simple temporal max/average pooling to obtain the whole video representation.
- adopt local 3D/(2+1)D convolutional operations to process local temporal window
时空信息在网络的顶端进行融合,再反向传播回来,可能会导致优化困难。所以作者提出multiple temporal aggregation。
#相关链接
- [CVPR 2020 ] 南京大学/腾讯 PCG 用于时序建模的轻量级行为识别模型 TEA
- TEA: Temporal Excitation and Aggregation for Action Recognition 阅读笔记
- CVPR2020 南大+腾讯 TEA 轻量级视频行为识别模型
- TEA: Temporal Excitation and Aggregation for Action Recognition
- Phoenix1327/tea-action-recognition
- 论文浏览(3) TEA: Temporal Excitation and Aggregation for Action Recognition
#BERT 相关笔记(一)
BERT 是在Transformer的结构基础上进行更新,所以主要看了一些基础的知识。
相关链接里前两个写的很好,结合着看可以加深理解。
#相关链接
- The Illustrated Transformer
- Transformer
- Transform 模型原理
- 自然语言处理中的自注意力机制(Self-attention Mechanism)
- Attention 机制详解(一)——Seq2Seq 中的 Attention
- 循环神经网络 RNN——深度学习第十章
- Attention 机制详解(二)——Self-Attention 与 Transformer
- 简说 Seq2Seq 原理及实现
- Seq2Seq 模型概述
#实验结果
较现有方法提升了0.8%:
| Method | Backbone | Frame | FLOPs × views | Val Top1 | Val Top5 |
|---|---|---|---|---|---|
| PAN Full | ResNet-50 + TSM | 8+8×4 | 67.7G × 1 | 50.5 | 79.2 |
| PAN Full with reverse | ResNet-50 + TSM | 8+8×4×2 | - | 51.3 | 79.9 |
#III. Plan for this week
- 看论文
- 毕业论文摘要部分初稿
- 继续改进现有代码