周报-20200910
Contents
| 2020-09-10 | 周报#04 | 刘潘 |
|---|
#I. Task achieved last week
- 《Gate-Shift Networks for Video Action Recognition》
- 《TSM Temporal Shift Module for Efficient Video Understanding》
- 《PAN: Towards Fast Action Recognition via Learning Persistence of Appearance》这篇是今年八月新发的,在something-something-v1数据集是目前的top1。
- TSM和PAN跑了实验测试了一下。
#II. Reports
#Gate-Shift Networks for Video Action Recognition
用于行为识别的Gate-Shift网络
在实践中,由于涉及大量的参数和计算,在缺乏足够大的数据集进行大规模训练的情况下,C3D可能表现不佳。
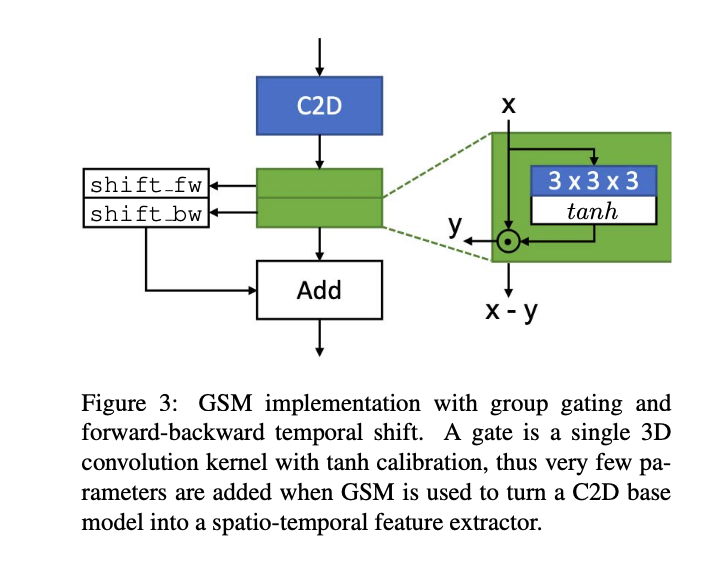
提出了一种Gate-Shift Module(GSM),将2D-CNN转换为高效的时空特征抽取器。
通过GSM插件,一个2D-CNN可以适应性地学习时间路由特性并将它们结合起来,并且几乎没有额外的附加参数和计算开销。
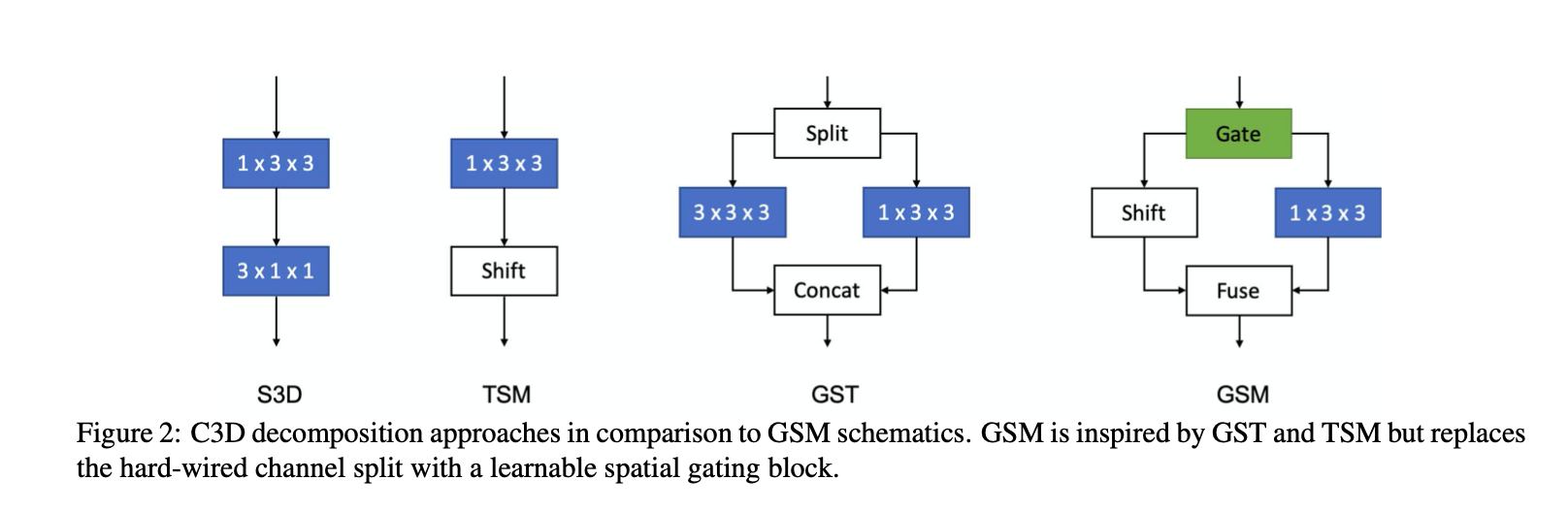
传统的方法演变:C3D -> 2D spatial + 1D temporal -> CSN -> GST(与分离信道组上的二维和三维卷积并行空间和时空交互建模) -> TSM(时域卷积可以被限制为硬编码的时移,使一些信道在时间上向前或向后移动)
所有这些现有的方法都学习具有硬连线连接和跨网络传播模式的结构化内核。
在网络中的任何一点上都没有数据依赖的决策来选择地通过不同的分支来路由特性,分组和随机的模式是在设计之初就固定的,并且学习如何随机是具有组合复杂性的。

From the experiments we conclude that adding GSM to the branch with the least number of convolution layers performs the best.
在卷积层最少的分支上添加GSM模块表现最好。
#TSM Temporal Shift Module for Efficient Video Understanding
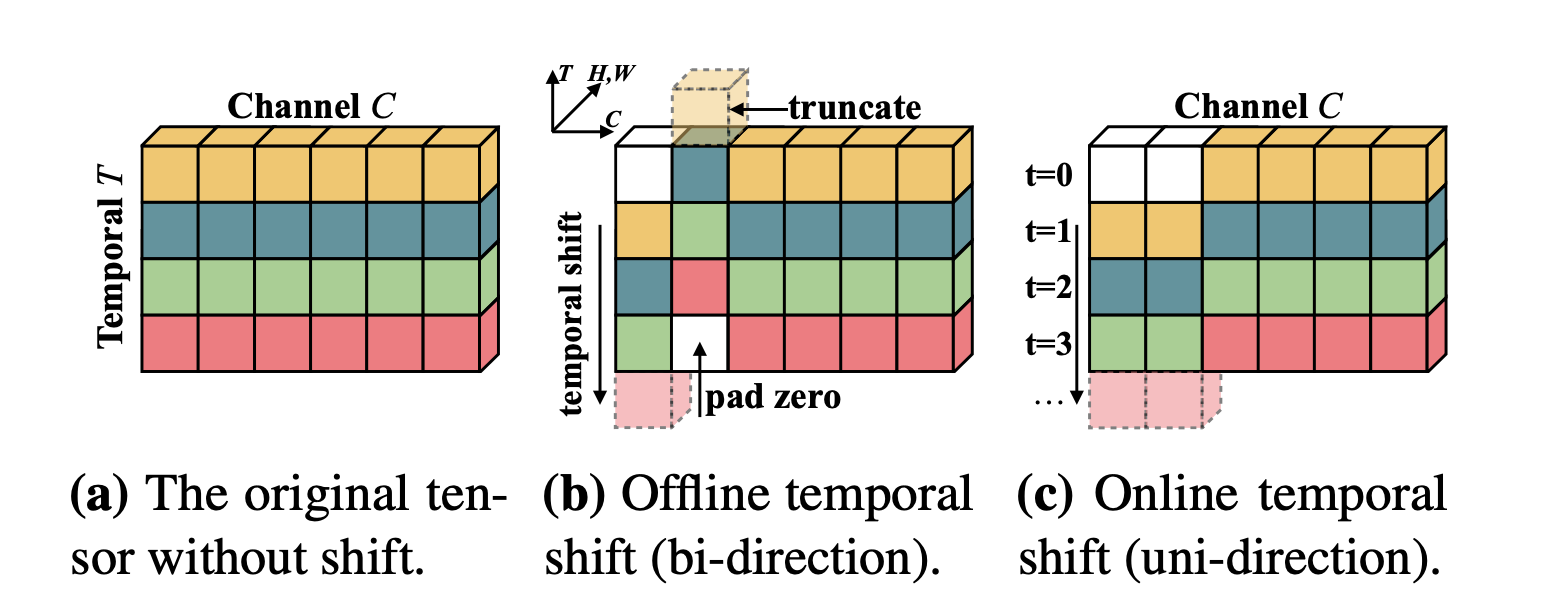
实现在 2D 模型上达到 3D 模型的精度,极大的降低了计算。
并不是所有的shift操作都可以达到效果的,虽然shift操作不需要额外的运算但是仍然需要数据的移动,太多的移动会带来延迟。
shift是增加时间特征的提取,太多的shift操作也会导致空间特征的提取受到影响。
改进的shift策略:并不是shift所有的channels,而是只选择性的shift其中的一部分,该策略能够有效的减少数据移动所带来的时间复杂度。
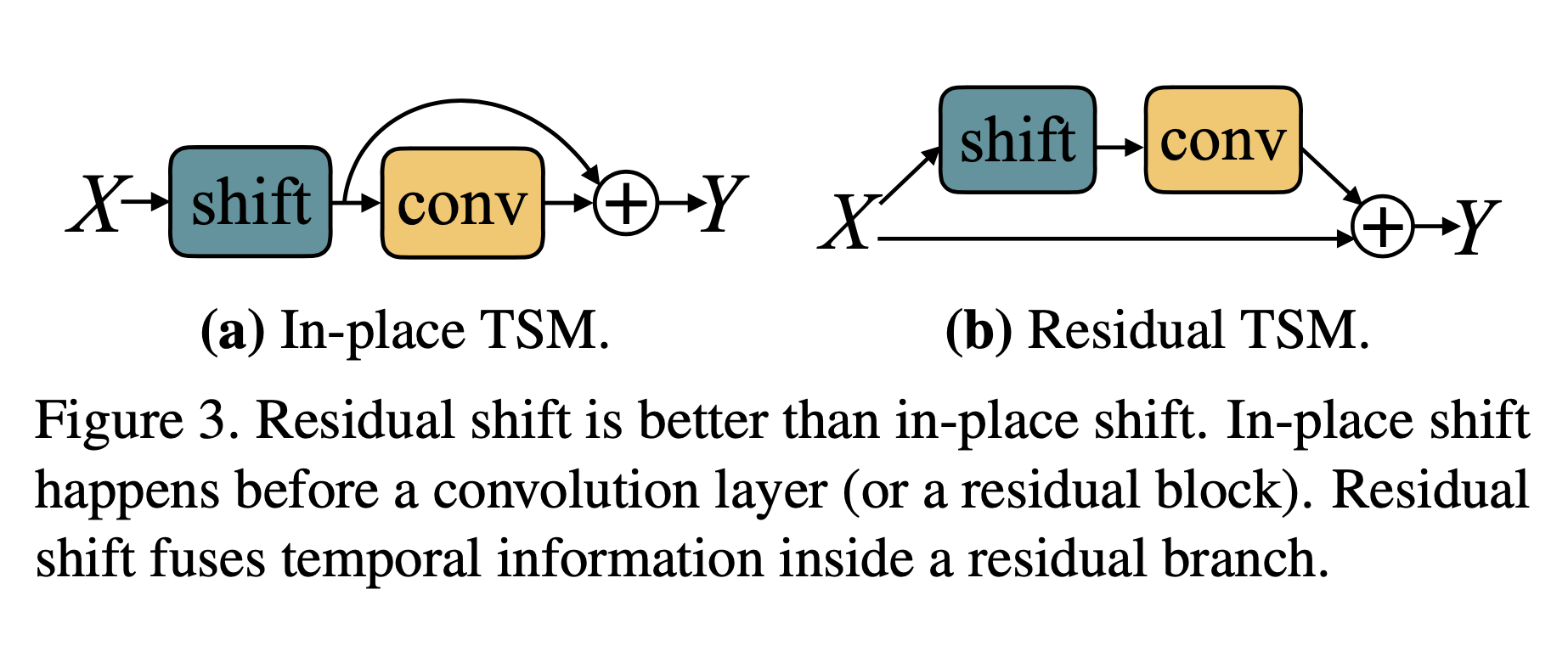
TSM 并不是直接被插入到从前往后的干道中的,而是以旁路的形式进行,因此在获得了时序信息的同时不会对二维卷积的空间信息进行损害。
同时作者对于一些实时的在线检测提出了相应的模型策略,不同于将第一层下移第二层上移这种:
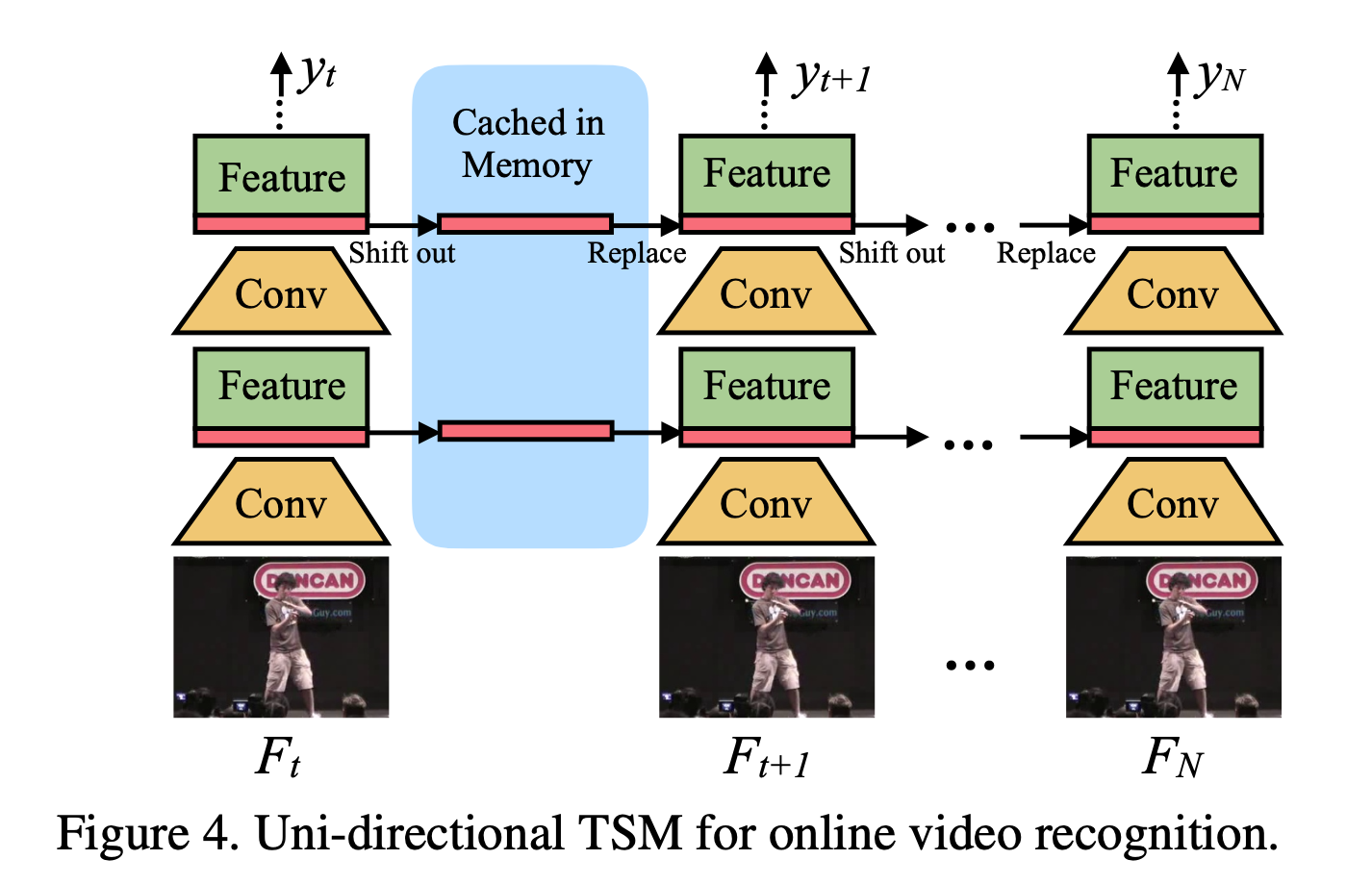
可以有相应的借鉴思路,并且这篇也是上一篇的基准之一。
#实验结果
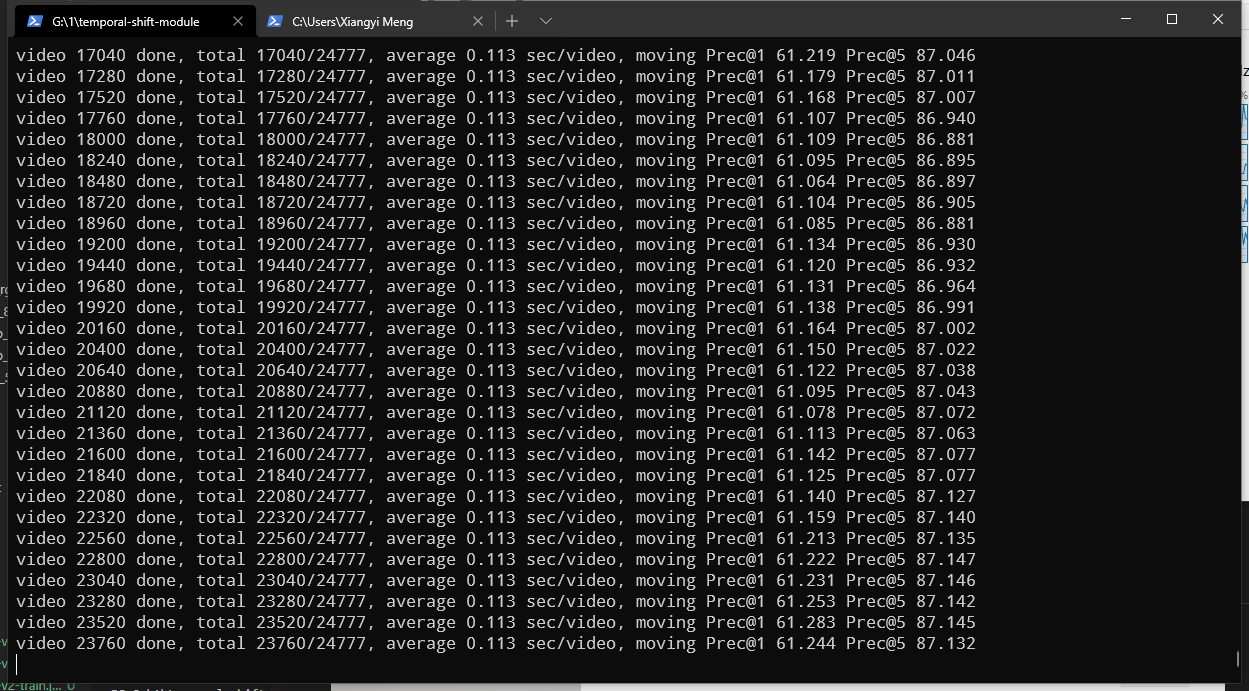
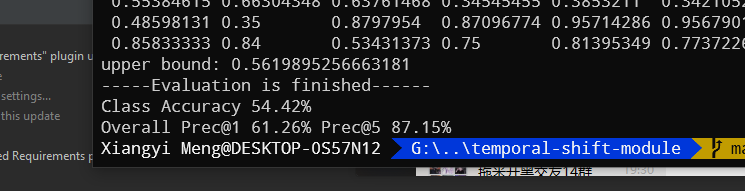
#相关链接
- https://github.com/mit-han-lab/temporal-shift-module
- 《TSM: Temporal Shift Module for Efficient Video Understanding》学习小记
- Temporal Shift Module
- TSM:Temporal Shift Module for 视频理解
- 【视频理解论文】——TSM:Temporal Shift Module for Efficient Video Understanding
- TSM:Temporal Shift Module for 视频理解
- Temporal Shift Module for Efficient Video Understanding
#PAN: Towards Fast Action Recognition via Learning Persistence of Appearance
比光流网络快了1000倍
Our PA is over 1000× faster (8196fps vs. 8fps) than conventional optical flow in terms of motion modeling speed
运动边界的微小位移在动作识别中起重要作用的角色。
According to the aforementioned anal- ysis, we can conclude that small displacements of motion boundaries play a vital role in action recognition.
低层的feature map之间的差异能更多地关注边界的变化。
the differences among low-level feature maps will pay more attention to the variations at boundaries.
In summary, differences in low-level feature maps can reflect small displacements of motion boundaries due to convolutional operations.
在UCF101上做实验表明在第一层效果最好。
We define the basic conv-layer as eight 7×7 convolutions with stride=1 and padding=3, so that the spatial resolutions of the obtained feature maps are not reduced.
两种编码策略:
PA as motion modality
PA as attention
第一种无论是从计算量上还是从准确率上都要更好。
可能原因是第二种融合方法导致图像的不平衡。
However, for e2, attending appearance feature maps with PA will highlight the motion boundaries, leading to the imbalanced appearance responses both inside and at the boundaries of the moving objects.
Various-timescale Aggregation Pooling
#实验结果
#Lite
1 | somethingv2: 174 classes |
#相关链接
#III. Plan for this week
- 看一下相关代码,了解一下他们改进的思路。
- 继续读论文。